Speech Recognition¶
Automatic Speech Recognition (ASR) is a technology that allows a machine to transform what a person is saying into text. An ASR system is usually composed by the following main elements (Fig. 1):
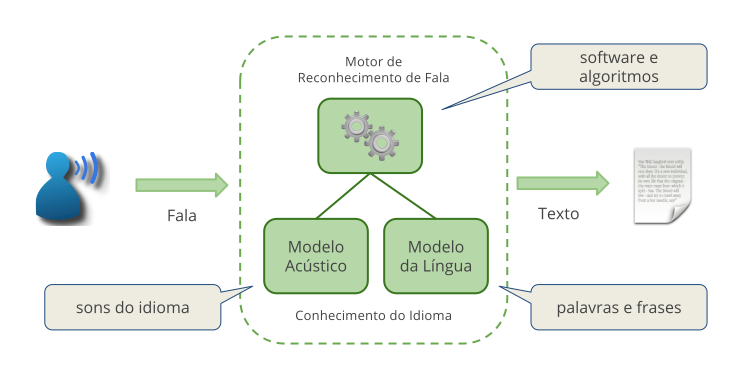
Fig. 1 Automatic voice recognition components.¶
- Recognition engine
Recognition engine software that deploys specific algorithms to execute all the phases of the speech recognition. It is responsible for precessing the audio before it is recognized. Techniques such as noise removal, detecting the start and end of the speech, and extracting features are generally featured in this system block.
- Acoustic model
Acoustic model set of data that mathematically represent the sounds that form the words of the language (called phones). Acoustic models are created based on large databases, recorded by several voice artists.
- Language model
Language model set of data that define how the words can be combined to form sentences in a given language. The language model can be formed by a grammar, containing rules written by a person, or by a free speech model, generated based on a large quantity of text and applied to spontaneous speech recognition.
General speech recognition dynamics are represented in Fig. 2. Speech recognition starts when a user utters a sentence into the system. The sentence corresponds to an audio signal. The audio signal is processed by the recognition engine that detects the speech segment (highlighted in the figure). The speech segment is then recognized and the corresponding sentence is returned by the system.
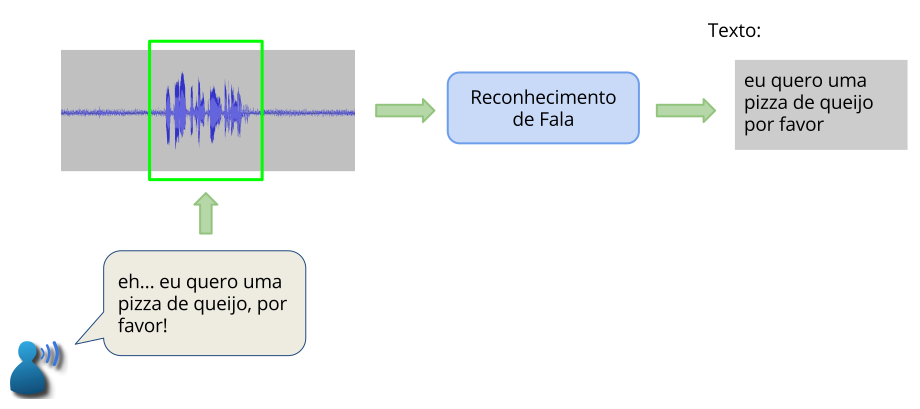
Fig. 2 General flow¶
When the source to be recognized is streamed audio, this audio is generally sent in short blocks, and recognition takes place as the blocks are received.
Some important information is returned by the system:
- Recognized Text
Speech recognition returns the most probable sentence encountered, based on the received speech segment. Besides the most likely match, the system may also return a list of the N most probable sentences (n-best list).
- Confidence Score
The confidence score is a numeric value that helps evaluate the certainty of the obtained result. In CPQD ASR, it is an integer value that goes from 0 (lowest confidence) to 100 (highest confidence). There are currently three available types: text confidence, semantic confidence and confidence per word.
- Semantic Interpretation
Semantic interpretation allows associating a variety of recognized sentences to a unique meaning (Fig. 3), making it easy the integration between the application and the speech recognition system, since instead of using the returned text directly, the application can use a standardized value. The interpretation can be a simple text value or a structured value (e.g. JSON).
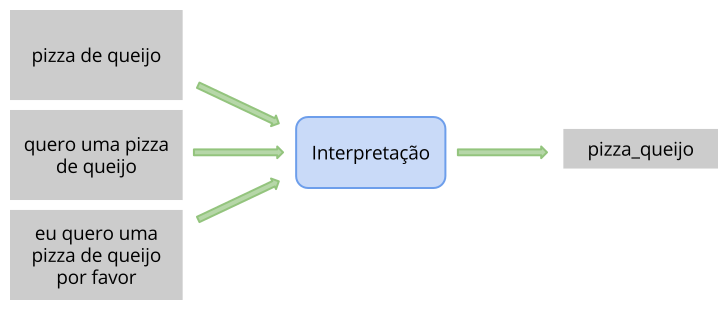
Fig. 3 Semantic Interpretation¶