Protocolo¶
A API WebSocket utiliza um conjunto de mensagens para acionar as funções de reconhecimento de fala do servidor. A conexão entre cliente e servidor é estabelecida de maneira padrão para essa tecnologia, ou seja, através de uma mensagem HTTP de handshake enviada pelo cliente, com indicação de upgrade da conexão para o protocolo WebSocket. O servidor irá responder o handshake e abrir uma conexão socket com o cliente. A partir desse momento, mensagens podem ser trocadas entre os dois endpoints.
A versão atual da API WebSocket é a 2.3. Ela é composta pelas seguintes mensagens.
Mensagem |
Descrição |
|---|---|
CREATE SESSION |
Cria uma sessão de reconhecimento de fala. Deve ser enviada pelo cliente após o estabelecimento de uma conexão WebSocket com o servidor. |
DEFINE GRAMMAR |
Carrega e compila uma gramática, permitindo que seja posteriormente usada no reconhecimento. |
START RECOGNITION |
Inicia o reconhecimento. Deve ser enviado antes do início da captura do áudio pelo cliente. Indica o modelo de língua que deve ser usado pelo servidor. Permite definir parâmetros para este reconhecimento. |
INTERPRET TEXT |
Realiza a interpretação semântica de um texto fornecido pelo cliente, usando a gramática indicada, de forma similar à mensagem START RECOGNITION. |
START INPUT TIMERS |
Inicia os temporizadores de início de fala e de reconhecimento. |
SET PARAMETERS |
Define parâmetros da sessão de reconhecimento. Deve ser enviada antes da mensagem START RECOGNITION. Os parâmetros serão válidos para todos os reconhecimentos dessa sessão. |
GET PARAMETERS |
Obtém o valor atual de parâmetros da sessão de reconhecimento. |
SEND AUDIO |
Transporta uma amostra do áudio a ser reconhecido. Recomenda-se o envio de amostras pequenas para obter o resultado do reconhecimento mais próximo do tempo real. |
CANCEL RECOGNITION |
Cancela o reconhecimento e descarta o resultado parcial. |
RELEASE SESSION |
Encerra a sessão de reconhecimento, liberando recursos alocados. Ao receber a mensagem, o servidor encerra a conexão WebSocket. |
Mensagem |
Descrição |
|---|---|
RESPONSE |
Resposta do servidor para qualquer mensagem enviada pelo cliente, exceto a mensagem SEND AUDIO que é enviada apenas em caso de erro. |
RECOGNITION RESULT |
Resultado do reconhecimento do áudio enviado, podendo conter um resultado parcial ou final. |
START OF SPEECH |
Indica que o servidor detectou o início de um segmento de fala nas amostras de áudio enviadas pelo cliente. O cliente deve continuar enviando as amostras de áudio para o servidor. |
END OF SPEECH |
Indica que o servidor detectou o fim de um segmento de fala nas amostras de áudio, e irá gerar o resultado final do reconhecimento deste segmento. |
O diagrama a seguir ilustra uma sequencia de uso das mensagens da API que permite realizar um reconhecimento de fala. A descrição detalhada de cada mensagem está na seção Formato das mensagens.
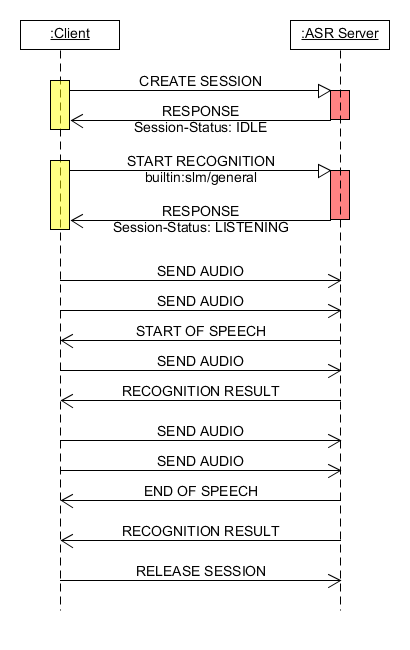
Fig. 11 Cenário de uso da API WebSocket.¶
A aplicação cliente abre uma conexão WebSocket com o Servidor CPqD ASR;
Após a abertura, o cliente deve enviar uma mensagem CREATE SESSION para criar uma sessão de reconhecimento, que é alocada exclusivamente para aquela conexão. A quantidade de sessões que podem ser criadas depende da quantidade de licenças disponíveis no servidor;
Para iniciar um reconhecimento, o cliente deve enviar uma mensagem START RECOGNITION, informando o modelo de língua (LM) que deve ser utilizado, seja um modelo de fala livre ou gramática;
O cliente deve iniciar a captura do áudio e enviar o stream de áudio em blocos de pequena duração, por exemplo, 200ms, através da mensagem SEND AUDIO. O servidor irá analisar continuamente as amostras de áudio recebidas, identificando o segmento de fala;
Quando o servidor detectar o início da fala, a mensagem START OF SPEECH será enviada para o cliente. Durante o processamento do segmento de fala, o servidor poderá enviar resultados parciais do reconhecimento através da mensagem RECOGNITION RESULT;
Quando o servidor detectar o fim da fala, a mensagem END OF SPEECH será enviada. O cliente não deve enviar novas amostras após o recebimento dessa mensagem. O servidor irá gerar o resultado final do reconhecimento para esse segmento, enviando novamente uma mensagem RECOGNITION RESULT;
Caso o stream de áudio seja finalizado antes do recebimento da mensagem END OF SPEECH, o cliente deve enviar a última mensagem SEND AUDIO com o header LastPacket definido como true. Isso fará com que o servidor encerre o reconhecimento e gere o resultado final para o segmento de fala;
Para realizar um novo reconhecimento, o cliente deverá enviar novamente uma mensagem START RECOGNITION;
A comunicação com o servidor pode então ser encerrada através da mensagem RELEASE SESSION ou pelo fechamento da conexão WebSocket.