Conceitos¶
O Reconhecimento Automático de Fala (Automatic Speech Recognition - ASR) é uma tecnologia que permite a uma máquina transcrever o que uma pessoa está dizendo. De modo geral, sistemas de ASR são compostos pelos seguintes elementos:
- Front-end: é responsável pelo processamento do áudio antes que ele seja decodificado. Técnicas de remoção de ruído, detecção de início e fim de fala, e extração de features geralmente estão presentes nesse bloco do sistema.
- Back-end: implementa os algoritmos que realizam o reconhecimento de fala. Este módulo recebe as features extraídas pelo front-end e, usando o conhecimento armazenado nos modelos acústico e da língua, produz as sentenças mais prováveis para um dado sinal de fala.
- Modelo acústico: representa, de forma matemática, os sons de determinado idioma (denominados fones). Modelos acústicos são criados a partir de grandes bases de fala, gravadas com vários locutores diferentes.
- Modelo da língua: emite a probabilidade de uma dada palavra ou combinação de palavras acontecer em uma língua. Modelos da língua são gerados a partir de uma grande quantidade de texto.
- Léxico: é responsável por indicar a transcrição fonética de cada uma das palavras que pode ser reconhecida pelo sistema de ASR.
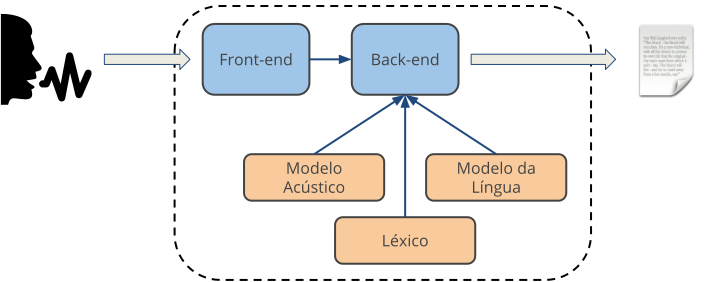
Visão geral de um sistema de reconhecimento automático de fala.
Na solução desenvolvida pelo CPqD, o front-end e o back-end são empacotados no motor de reconhecimento de fala. Já o léxico e os modelos acústico e da língua são empacotados na forma de pacotes do idioma. Todos esses componentes fazem parte do servidor CPqD ASR.