Reconhecimento de fala¶
O Reconhecimento Automático de Fala (Automatic Speech Recognition - ASR) é uma tecnologia que permite a uma máquina transformar em texto o que uma pessoa está falando. Um sistema de ASR é normalmente constituído pelos seguintes elementos principais (Fig. 1):
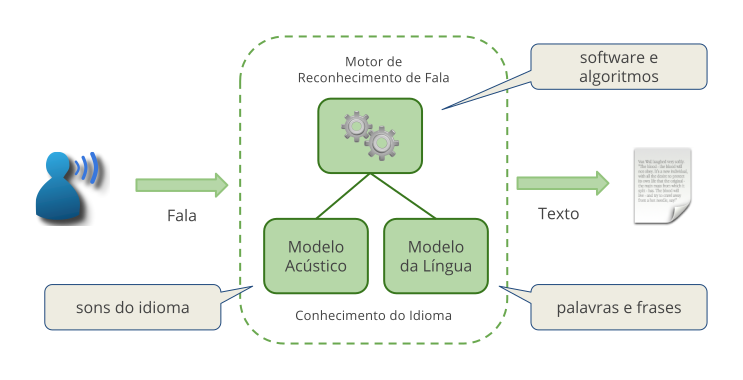
Fig. 1 Componentes de um sistema de reconhecimento automático de fala.¶
- Motor de reconhecimento
Software que implementa algoritmos específicos para executar todas as fases do reconhecimento de fala. Ele é responsável pelo processamento do áudio antes que ele seja reconhecido. Técnicas de remoção de ruído, detecção de início e fim de fala, e extração de features geralmente estão presentes nesse bloco do sistema.
- Modelo acústico
Conjunto de dados que representa matematicamente os sons que formam as palavras do idioma (denominados fones). Modelos acústicos são criados a partir de grandes bases de fala, gravadas com vários locutores.
- Modelo da língua
Conjunto de dados que define como as palavras podem ser combinadas para formar as frases do idioma. O modelo da língua pode ser constituído por uma gramática composta por regras escritas por uma pessoa, ou por um modelo para fala livre gerado a partir de uma grande quantidade de texto e aplicado no reconhecimento de fala espontânea.
A dinâmica geral do reconhecimento de fala é representada em Fig. 2. O reconhecimento de fala inicia com o usuário falando uma frase ao sistema. A frase corresponde a um sinal de áudio. O sinal de áudio é processado pelo motor de reconhecimento que realiza a detecção do segmento de fala (destacado na figura). O segmento de fala é então reconhecido e a frase correspondente é retornada pelo sistema.
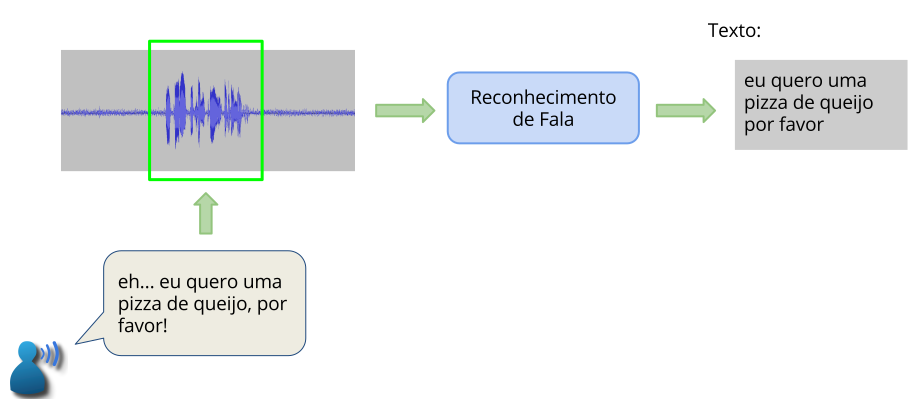
Fig. 2 Fluxo geral do reconhecimento¶
Quando o reconhecimento tem como fonte um streaming de áudio, este áudio é geralmente enviado em blocos curtos e o reconhecimento é executado à medida que esses blocos são recebidos.
Algumas informações importantes são retornadas pelo sistema:
- Texto reconhecido
O reconhecimento de fala retorna a frase mais provável encontrada a partir do segmento de fala recebido. Além da frase mais provável, o sistema pode retornar também a lista das N frases mais prováveis (n-best list).
- Índice de confiança
O índice de confiança é um valor numérico que ajuda a avaliar a certeza no resultado obtido. No CPqD ASR, ele é um valor inteiro que varia de 0 (menor confiança) a 100 (maior confiança). Há atualmente três tipos disponíveis: confiança do texto, confiança semântica e confiança por palavra.
- Interpretação semântica
A interpretação semântica permite associar uma variedade de frases reconhecidas a um significado único (Fig. 3), facilitando a integração entre a aplicação e o sistema de reconhecimento de fala, pois ao invés de usar diretamente o texto retornado, a aplicação pode usar um valor padronizado. A interpretação pode ser um valor textual simples ou um valor estruturado (ex. JSON).
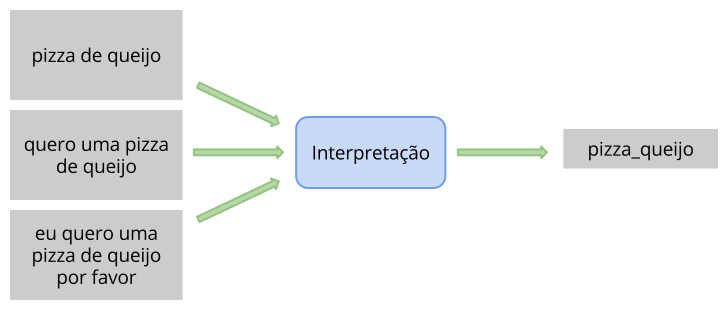
Fig. 3 Interpretação semântica¶
Diarização online
Adicionalmente, a partir da versão 3.6.0, dispomos agora do serviço de diarização.
A diarização traz como principal benefício a identificação automática de quem falou e quando, o que torna a análise de conversas muito mais rápida e acionável, facilitando o entendimento do diálogo, a separação de falas entre participantes e a geração de insights imediatos.
- Modelo de diarização
Conjunto de dados e algoritmos que permitem identificar e segmentar, ao longo do tempo, as diferentes vozes presentes em um áudio. O modelo de diarização é treinado a partir de grandes bases de fala com múltiplos locutores e aprende características acústicas que distinguem uma voz da outra, possibilitando agrupar trechos de áudio por locutor e indicar quem falou quando, sem necessariamente identificar a pessoa.