Modo contínuo¶
O reconhecimento de fala pode ser realizado de duas maneiras diferentes: “modo simples” ou “modo contínuo”.
O modo simples é o modo padrão de funcionamento (decoder.continuousMode=false). O reconhecimento é realizado apenas para o primeiro segmento de fala identificado no áudio, ou seja, todo o áudio posterior a um trecho de silêncio maior que valor do parâmetro endpointer.waitEnd é descartado (veja figura seguinte).
Este modo é normalmente usado em aplicações de diálogo nas quais se espera a resposta curta do usuário a uma pergunta da aplicação. Ele não é apropriado a transcrição de áudios longos com várias frases. Ele é usado com fala livre ou gramáticas.
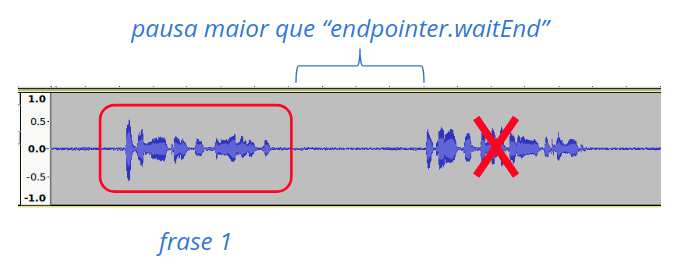
Fig. 13 Reconhecimento no modo simples.¶
No modo contínuo, o reconhecimento é realizado para todos os segmento de fala do áudio de entrada. O reconhecimento geralmente continua até que o áudio seja finalizado (veja figura seguinte).
Este modo é normalmente usado com modelo de fala livre, em aplicações de transcrição de áudio longo, contendo muitas frases e pausas, com reconhecimento em tempo real ou não.
Aviso
Para usar o modo contínuo, a licença deve estar liberada para ele e o parâmetro decoder.continuousMode=true.
O modo contínuo está disponível nas APIs WebSocket, REST e GRPC e tem uma dinâmica específica de funcionamento. Para maiores informações, consulte as seções sobre modo contínuo específico da API que será usada.
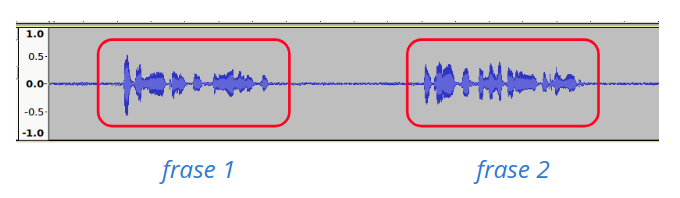
Fig. 14 Reconhecimento no modo contínuo.¶