Formatação¶
Esta seção tem por objetivo informar ao usuário do Texto Fala as regras de formatação de texto assumidas pelo software, bem como os recursos de controle da fala sintetizada disponíveis através do texto de entrada. Os comentários aqui inseridos são genéricos tanto para o idioma do português do Brasil, quanto ao espanhol latino-americano, porém os exemplos citados estão baseados no português do Brasil.
Restrições do Texto de Entrada¶
Conjunto de caracteres¶
O Texto Fala está preparado para interpretar arquivos e buffers de texto puro, sem cabeçalhos ou caracteres de formatação.
Caso o texto a sintetizar seja produzido através de programas de processamento de texto, o formato selecionado para gravação do texto em disco deve ser o de texto puro (geralmente com extensão “txt”); não devem ser usados formatos que incluam informações de formatação, tais como “doc”, “docx”, “rtf”, “odt”, “sxw”, “pdf”, “ps” e outros.
Além disso, o texto deve estar codificado em um dos padrões reconhecidos pelo Texto Fala:
ISO-8859-15, geralmente empregado pelo Windows e por algumas versões de Unix/Linux;
UTF-8 (apenas para os caracteres representados na tabela ISO-8859-15), comum em sistemas Unix/Linux e muitas vezes encontrado também em sistemas Windows;
Caracteres fora desses padrões serão ignorados.
Limite de tamanho do texto¶
O texto de entrada ao Texto Fala deve ter, como máximo, 1.024.000 caracteres. Caso esse limite seja excedido, um erro será retornado pelo programa informando que o texto é muito longo. Para sintetizar textos maiores que esse limite, a aplicação que usa o Texto Fala deve quebrar o texto de entrada em blocos menores que não ultrapassem 1.024.000 caracteres cada um.
Formatação do Texto de Entrada¶
Tratamento de pontuação¶
A correta pontuação do texto de entrada é essencial para a qualidade da fala sintetizada, tendo influência - sobretudo - na inserção de pausas e na entonação da fala. Os seguintes caracteres de pontuação são reconhecidos pelo Texto Fala: “.” (ponto), “,” (vírgula), “;” (ponto e vírgula), “:” (dois pontos), “!” (ponto de exclamação), “?” (ponto de interrogação), “(” (abre parênteses), “)” (fecha parênteses), “[” (abre colchetes), “]” (fecha colchetes), “{” (abre chaves) e “}” (fecha chaves). Caracteres de aspas e apóstrofo serão ignorados.
O ponto pode ser um terminador de sentença, parte de uma abreviação ou um separador de algarismos. O Léxico de Abreviações será consultado antes que um ponto seja considerado terminador de sentença, para saber se não forma parte de uma abreviação.
Caso a última palavra de um parágrafo seja uma abreviação terminada por ponto, é necessário inserir um ponto adicional separado por espaço para que o sistema reconheça o final de parágrafo. Por exemplo: o texto “Estudam dança, canto, capoeira etc. Os cursos são gratuitos.”, no qual o ponto após “etc” desempenha ao mesmo tempo papel de terminador de sentença e indicador de abreviação, deve ser grafado: “Estudam dança, canto, capoeira etc. . Os cursos são gratuitos.”
Tratamento do traço (“-”)¶
Se o traço fizer parte de um padrão específico, será tratado conforme descrito na seção correspondente deste documento. Caso contrário, o Texto Fala identificará se o mesmo deve ser verbalizado ou não. Nos casos que o traço faz parte de uma quantia ou um número negativo, por exemplo “-18” (“menos dezoito”), ele será convertido para a palavra “menos”. Caso ocorra no interior de uma sequência de símbolos sem padrão especifico, por exemplo “#-/%” (“numeral traço barra por cento”) ou “$&-01” (“cifrão ê comercial traço zero hum”), será convertido na palavra “traço”.
Tratamento do caractere de fim de parágrafo¶
O caractere de fim de parágrafo enter age como um terminador de sentença. Caso não haja um caractere de pontuação antes do fim de parágrafo, com as configurações Text.SSML desabilitada e Text.BreakLine habilitada no arquivo de configuração do Texto Fala (tts.conf), um ponto final é automaticamente inserido pelo sistema.
Para tratamento com SSML (Text.SSML habilitada), recomendamos o uso das tags <s> e <p> (SSML), caso a pontuação final não esteja explícita no texto.
Tratamento de expressões contendo números¶
Números genéricos¶
Números inteiros ou decimais podem conter, além de algarismos, o “.” (ponto) e a “,” (vírgula). O ponto é usado como separador de grupos de 3 algarismos. Caso haja uma quantidade de algarismos diferente de 3 entre dois pontos, o número será pronunciado algarismo a algarismo e os pontos serão lidos explicitamente (a exceção é o grupo de dígitos mais à esquerda do número, que pode conter 1, 2 ou 3 algarismos).
A vírgula indica a separação entre a parte inteira e a parte fracionária do número. Caso seja utilizado ponto ao invés de vírgula, este será lido explicitamente. Por exemplo, o número “120.0” será verbalizado “cento e vinte ponto zero”.
Números iniciados pelo algarismo “0” (zero) serão pronunciados algarismo a algarismo; por exemplo, “0123” será lido “zero hum dois três”.
A seguir encontram-se alguns exemplos do tratamento efetuado para números:
“2023343” ou “2.023.343” será lido “dois milhões vinte e três mil trezentos e quarenta e três”.
“1912” ou “1.912” será lido “mil novecentos e doze”.
“123 343 567” será lido “cento e vinte e três trezentos e quarenta e três quinhentos e sessenta e sete”.
“012” será lido “zero um dois”.
“36,55” será lido “trinta e seis vírgula cinquenta e cinco”.
“1.025,2” será lido “mil e vinte e cinco vírgula dois”.
“10,1,245” será lido “dez , hum , duzentos e quarenta e cinco”.
Caso a detecção automática de gênero esteja ativa (ver embaixo Tags de Programação), a concordância dos números pode ser feita no feminino, conforme a palavra que sucede o número. Por exemplo:
“1 carro” será lido “um carro”, mas “1 casa” será lido “uma casa”.
“200.000 carros” será lido “duzentos mil carros”, mas “200.000 casas” será lido “duzentas mil casas”.
Embora as regras de detecção de gênero funcionem corretamente para a maioria das palavras, eventuais erros de concordância podem ocorrer. Uma possível solução para este problema é desabilitar a detecção automática de gênero, o que pode ser feito pela inserção da tag say-as “no-gender” no texto de entrada (ver Tags de Programação). Outra opção é criar uma exceção às regras de detecção de gênero (neste caso, favor contactar o CPQD).
Números ordinais¶
Números INTEIROS seguidos SEM ESPAÇO dos símbolos de ordinal ou de grau, ou das letras “a” “o”, ou das strings «.a», «.o», serão considerados números ordinais.
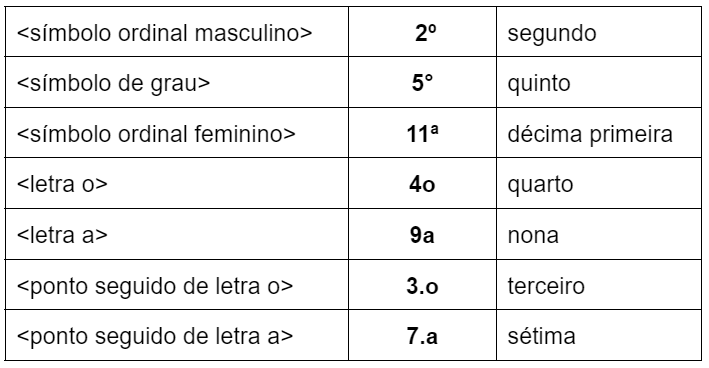
Exemplos de uso e pronúncias
Números fracionários seguidos SEM ESPAÇO dos símbolos de ordinal ou de grau, serão lidos como «graus». Ex: «10,8º»: dez vírgula oito graus; «52,3°»: cinquenta e dois vírgula três graus.
Para que um número inteiro seguido SEM ESPAÇO dos símbolos de ordinal ou de grau seja interpretado como uma temperatura, é necessário que após o símbolo venha um caracter de temperatura (“C” de celsius, “F” de farenheit, “K” de kelvin, “r” de réarmur ou “Ra” de rankine). Não pode haver espaço entre o símbolo e o char de temperatura. Ex: 37ºC; 12ºK.
Para que um número inteiro seguido dos símbolos de ordinal ou de grau seja interpretado como uma direção, é necessário que após o símbolo venha um caracter de direção (“N” de norte, “S” de sul, “L» ou «E” de leste, “O” ou “W” de oeste). Não pode haver espaço entre o símbolo e o caracter de temperatura. Ex: 37ºN; 12ºS.
Havendo espaço entre o número e o símbolo de grau ou ordinal, a string nunca será interpretada como um número ordinal.
Horários e durações¶
- Horários e durações devem ser indicados usando letras “h”, “hr”, “hrs” ou “hs”, ou pelo símbolo “:” (dois pontos). Por exemplo:
“5h00”, “5:00”, “5h”, “5 hr”, “5 hs” ou “5hrs” será lido “cinco horas” “5:45” ou “5h45” será lido “cinco horas e quarenta e cinco minutos”.
- No caso que os segundos estejam presentes, eles também serão verbalizados. Por exemplo:
“5:45:12” será lido “cinco horas, quarenta e cinco minutos e doze segundos”.
- Unidades de tempo indicados pelas letras “h”, “hr”, “hrs” ou “hs” podem ser opcionalmente seguidas por “m”, “min”, “s”, “seg” . Por exemplo:
“5h15m” ou “5hr15min” será lido “cinco horas e quinze minutos”.
- Além desses formatos, os minutos podem ser representados por apóstrofo e os segundos por aspas. Por exemplo:
“5’12”” será lido “cinco minutos e doze segundos”.
- Horários com “AM” e “PM” serão lidos acrescentando “á ême” ou “pê ême”, respectivamente. Por exemplo:
“5:00 PM” será lido “cinco horas pê ême”. “8:15am” será lido “oito horas e quinze minutos á ême”.
- Durações de tempo escritas isoladamente só serão interpretadas corretamente se forem usados os formatos “h”, “hr”, “hrs”, “hs” ou “min”. Por exemplo:
“5min” ou “5 min» será lido “cinco minutos”.
O formato “5h45m” também é aceito, mas “5m” não; neste último caso, “m” será interpretado como a unidade de medida “metro” (ver Unidades de medida mais à frente nesta seção).
- Durações em segundos serão interpretadas corretamente se acompanhadas de minutos e/ou horas. Por exemplo:
“7h21m7s” ou “7hs21min7seg» será lido “7 horas, 21 minutos e 7 segundos”; “2min18seg” será lido “2 minutos e 18 segundos”; e “5hr45s” será lido “cinco horas e quarenta e cinco segundos”.
Datas¶
Datas devem ser especificadas por três grupos de dígitos separados por barra ou por traço, sendo possível utilizar excepcionalmente palavras ou abreviações dos meses no lugar apropriado. Esta condição também se aplica a casos em que apenas dois grupos de dígitos componham a data.
Em casos onde a sequência de caracteres é formada por apenas dois grupos de números e um separador, será feita a expansão elemento a elemento devido à ambiguidade entre o texto ser uma data ou uma outra expressão. Se a sequência de caracteres contiver números fora da faixa de datas possíveis (considerando meses com 30 ou 31 dias e anos bissextos), a sequência será expandida elemento a elemento.
Nos casos onde letras sejam utilizadas no lugar do mês ou no uso de datas irônicas, como “30/Fev”, o texto será interpretado como uma data. Alguns exemplos:
“16/03/1994” ou “16/3/1994” será lido “dezesseis de março de mil novecentos e noventa e quatro”.
“05/10/94” ou “5/Out/94” será lido “cinco de outubro de noventa e quatro”.
“16/mar” ou “16/março” será lido “dezesseis de março”.
“07/15” e “07-15” serão lidos “zero sete barra quinze” e “zero sete traço quinze” respectivamente.
“29/02/1996” será lido “vinte e nove de fevereiro de mil novecentos e noventa e seis”.
“29/Fev/1997” será lido “vinte e nove de fevereiro de mil novecentos e noventa e sete”.
“30/Fev/1999” será lido “trinta de fevereiro de mil novecentos e noventa e nove”, pois como o mês está escrito com letras, é considerada uma data irônica.
“30/02/1999” será lido “trinta barra zero dois barra mil novecentos e noventa e nove”, pois essa não é uma data válida.
Quantias monetárias¶
O Texto Fala interpreta valores monetários em reais, dólares, euros e libras. Valores precedidos por “R$” serão convertidos para “reais”, precedidos por “$”, “£” e “€” serão convertidos para “dólares”, “euros” e “libras”, respectivamente. Adicionalmente, códigos ISO utilizados para moedas serão interpretados como tais. Os plurais e o gênero também serão considerados. Em casos que existam mais de dois dígitos após a vírgula, a parte fracionária será soletrada. Alguns exemplos:
“R$20” ou “R$ 20” ou “R$20,00” ou “BRL 20,00” será lido “vinte reais”.
“R$20,10” ou “R$ 20,10” será lido “vinte reais , e dez centavos”.
“R$0,10” ou “R$ 0,10” será lido “dez centavos”.
“-R$ 20” ou “-R$20,00” será lido “menos vinte reais”.
“US$20” ou “US$ 20” ou “US$20,00” ou “USD 20,00” será lido “vinte dólares”.
“US$20,10” ou “US$ 20,10” será lido “vinte dólares , e dez centavos”.
“US$0,10” ou “US$ 0,10” será lido “dez centavos de dólar”.
-R$20,30 será lido «menos vinte reais e trinta centavos».
R$-20,30 será lido «menos vinte reais e trinta centavos».
Quando os símbolos monetários não precedem um número, eles serão lidos por extenso. Por exemplo, “$” será lido “cifrão” e “R$” será lido “reais”. O sinal de «menos» pode ir antes do símbolo monetário ou entre o símbolo monetário e a quantia, mas em ambos casos NÃO PODE HAVER ESPAÇO entre o «menos» e o símbolo monetário ou a quantia. Exemplos de escrita errada de quantias negativas:
“- R$20,30” será lido «traço vinte reais e trinta centavos».
“R$ - 20,30” será lido «reais , vinte vírgula trinta».
Unidades de medida¶
O Texto Fala é capaz de interpretar algumas unidades de medida. As unidades são interpretadas como tal somente quando sucedem um conjunto de dígitos, podendo ser ou não precedidas por caracteres de espaçamento. Algumas unidades são sensíveis à caixa das letras. As unidades são automaticamente ajustadas para singular ou plural, conforme o caso. Algumas medidas são consideradas menos ambíguas e podem ser expandidas mesmo sem um número na frente dela. Neste caso, a forma plural é assumida. Exemplos:
“1 km/h” ou “1km/h” é lido “hum quilômetro por hora”
“3 cm” ou “3cm” é lido “três centímetros”
“90 m²” é lido “noventa metros quadrados”
“km/h” é lido “quilômetros por hora”
“mmHg” é lido “milímetros de mercúrio”.
Temperaturas¶
Temperaturas são indicadas pelo símbolo “°” (grau) após um número e precedendo uma abreviação de temperatura. As abreviações de temperatura aceitas pelo Texto Fala são: “C” (celsius), “F” (Fahrenheit), “K” (Kelvin), “R” (Reamur) ou “Ra” (Ranquine). Formas em plural são reconhecidas pelo sistema. Exemplos:
“4°F” ou “4 °F” ou “4 ° F” será lido “quatro graus fahrenheit”
“1°C” ou “1 °C” ou “1 ° C” será lido “um grau celsius”
Direções geográficas¶
Direções geográficas são indicadas pelo símbolo “°” (grau) após um número e precedendo uma abreviação de direção. As abreviações de direção aceitas pelo Texto Fala são: “N” (norte), “S” (sul), “L” (leste), “E” (leste), “W” (oeste) ou “O” (oeste). Formas em plural são reconhecidas pelo sistema. Exemplos:
“1°N” ou “1 °N” ou “1 ° N” será lido “um grau norte”
“4°S” ou “4 °S” ou “4 ° S” será lido “quatro graus sul”
E-mails e URLs¶
Endereços de e-mail e URLs são tratados quando caracteres indicativos, como “@” e “.”, são incluídos em uma sequência de caracteres sem espaços. Exemplos:
maria@cpqd.com.br é convertido para “maria , arroba cê pê quê dê , ponto com , ponto bê érre”
www.google.com/home.html é convertido para “dábliu dábliu dábliu ponto google , ponto com, barra home, ponto agá tê ême éle”
Páginas conhecidas da web com pronúncias excepcionais para o português brasileiro são tratadas como exceções fonéticas. Caso seja necessário incluir alguma página específica, favor entrar em contato com o CPQD.
Números de telefone¶
Números de telefone nos formatos especificados abaixo são tratados de forma que pares de algarismos sejam falados juntos e grupos maiores sejam soletrados (adicionalmente, introduze-se uma pausa entre grupos de algarismos separados por espaços, traços e, em alguns casos, parênteses). Por exemplo, um DDD normalmente será verbalizado como um número único (“11” será convertido para “onze”), enquanto os outros grupos de números serão soletrados criando pausas rítmicas. Os seguintes formatos de números serão interpretados como números de telefone:
O “#” representa qualquer dígito.
Números Locais:
0300 ###-####
0300 ### ####
0500 ###-####
0500 ### ####
0800 ###-####
0800 ### ####
0900 ###-####
0900 ### ####
####-####
#####-####
# #### ####
# ####-####
Números Locais com DDD:
(0##) ####-####
(0##) #####-####
(##) #### ####
(##) ####-####
(##) ##### ####
(##) #####-####
(##) # #### ####
(##) # ####-####
Os números Internacionais devem ser utilizados da seguinte forma:
Código País + código Localidade + número de telefone
Exemplo: +1 408 480-1520
(## ##) ####-####
(## ##) #####-####
(+## ##) ####-####
(+## ##) #####-####
+# ### ### ####
+# ### ###-####
+# ### #### ####
+# ### ####-####
+# ### ##### ####
+# ### #####-####
+# ### # #### ####
+# ### # ####-####
+## ### ### ####
+## ### ###-####
+## ### #### ####
+## ### ####-####
+## ### ##### ####
+## ### #####-####
+## ### # #### ####
+## ### # ####-####
+# (###) ### ####
+# (###) ###-####
+# (###) #### ####
+# (###) ####-####
+# (###) ##### ####
+# (###) #####-####
+# (###) # #### ####
+# (###) # ####-####
+## (###) ### ####
+## (###) ###-####
+## (###) #### ####
+## (###) ####-####
+## (###) ##### ####
+## (###) #####-####
+## (###) # #### ####
+## (###) # ####-####
Desta forma, o número telefônico “(16) 9 8294 0316” será lido “dezesseis, nove , oito dois nove quatro , zero três hum seis”.
Se a sequência de números não estiver em um dos formatos especificados, não será interpretada como número telefônico e será lida de forma diferente. Por exemplo “(9) 99-9999-999” será convertida para “nove , noventa e nove , nove mil novecentos e noventa e nove , novecentos e noventa e nove”.
Números e Tipos de Documentos¶
O “#” representa qualquer dígito.
Os seguintes formatos de números serão interpretados como CPF, CNPJ, RG, RNE (Registro Nacional de Estrangeiro) e CEP respectivamente:
- CPF: ###.###.###-##
Lido dígito a dígito e o hifen será vocalizado inserindo uma pausa nesse local.
- CNPJ: ##.###.###/####-##
Lido dígito a dígito, a barra e o hifen serão vocalizados inserindo uma pausa nesses locais.
- RG: ##.###.###-#
Lido dígito a dígito e o hifen será vocalizado inserindo uma pausa nesse local.
O «A» representa qualquer letra, maiúscula ou minúscula.
- RNE: A######-A OU A######-#
Lido caracter a caracter, inserindo uma pausa no lugar do hífen (o hífen não será lido).
- CEP: #####-###
Lido dígito a dígito, inserindo uma pausa no lugar do hífen (o hífen não será lido).
Se a sequência de números não estiver em um dos formatos especificados, ela não será interpretada como um número de documento. Por exemplo “9999999-9” será lido “nove milhões novecentos e noventa e nove mil novecentos e noventa e nove traço nove”.
Diretórios¶
Diretórios comuns no padrão Linux serão interpretados de forma a não serem confundidos com outras sequências de letras, números e símbolos. Por exemplo: “/usr/bruno” será lido “barra user barra bruno”. A Tabela 1 lista os elementos tratados na leitura de diretórios e a forma como são verbalizados.
Tabela 1: Elementos tratados na leitura de diretórios pelo Texto Fala
Palavra |
Verbalização |
|---|---|
bin |
bin |
boot |
boot |
dev |
dev |
etc |
ê tê cê |
home |
home |
lib |
lib |
media |
media |
mnt |
mount |
opt |
ó pê tê |
sbin |
esse bin |
srv |
ésse érre vê |
tmp |
temp |
usr |
user |
var |
var |
root |
root |
proc |
proc |
/ |
barra |
Outras combinações de dígitos¶
Para outras combinações de dígitos, a leitura é elemento a elemento normalmente separados por espaços. Por exemplo “120 1999 10” é lido “cento e vinte mil novecentos e noventa e nove dez”.
O gênero do número é modificado sempre que for possível identificar o género do substantivo após o número. Por exemplo “2 casas” é convertido para “duas casas”.
Tags de Programação¶
O Texto Fala disponibiliza tags com o objetivo de controlar a forma como as palavras são vocalizadas, provendo facilidades tais como: leitura em modo soletrado, tratamento diferenciado para números, inserção de pausas e modificação do ritmo da fala, além de switches para modificar a maneira de verbalizar gênero, frações, abreviações dos estados brasileiros e datas, entre outros. Isto é feito através do recurso SSML (Speech Synthesis Markup Language). Para detalhes e uso deste recurso, ver a seção Interpretador SSML.
Abreviações, Siglas e o Léxico de Abreviações¶
Tratamento de siglas¶
O Texto Fala considera como siglas as palavras que contém somente consoantes e, neste caso, soletra as mesmas.
Também são soletradas, em geral, palavras que incluam símbolos não alfabéticos. O Apêndice 1 contém uma tabela com a forma em que o Texto Fala lê os caracteres no modo soletrado.
Siglas que não sejam automaticamente reconhecidas como tal, podem ser soletradas usando a tag SSML say-as com o atributo spell. Outra opção é incluí-las no léxico de abreviações, indicando explicitamente como devem ser lidas.
Tratamento de abreviações¶
Abreviações são especificadas em um léxico padrão (Léxico de Abreviações), que o sistema lê durante sua inicialização. Quando um termo contido neste léxico é encontrado no texto de entrada, ele é substituído pela sua forma expandida. Por exemplo, a palavra “av” encontra-se definida no léxico como “avenida”, portanto, será lida desta forma sempre que ocorrer no texto de entrada.
Caso queira uma adequação específica do Léxico de Abreviações para sua aplicação, consulte o CPQD. Existe um outro léxico de abreviações editável pelo usuário, que pode ou não estar presente no sistema conforme sua configuração; este Léxico do Usuário está descrito mais abaixo.
Nota
As entradas presentes no Léxico do Usuário têm precedência em relação às entradas presentes no Léxico Padrão.
Perceba que uma mesma abreviação pode ter significados diferentes em função do contexto. Por exemplo, em “S. Paulo” a abreviação “s.” significa “são”, enquanto em “Conjunto 13, S. 17” a mesma abreviação significa “sala”. Ambiguidades podem ocorrer, inclusive, dentro de um mesmo contexto semântico: por exemplo, em “S. André” a abreviação “s.” significa “santo” ao invés de “são”. O Texto Fala permite definir apenas uma expansão para cada abreviação, não sendo possível diferenciar contextos semânticos. Caso haja ambiguidade, a aplicação deve optar pela expansão mais frequente ou que cause menor efeito colateral ou, ainda, realizar ela própria a expansão que considerar mais conveniente antes de entregar o texto ao Texto Fala.
A tabela seguinte especifica alguns exemplos de abreviações reconhecidas pelo Texto Fala. Havendo necessidade de adequação de abreviações, favor contactar o CPQD.
Tabela 2 - Abreviações reconhecidas pelo Texto Fala
Símbolo
Expansão
+/-
mais ou menos
&c
et cétera
pag.
página
pág.
página
av*
avenida
pags.
páginas
págs.
páginas
pp.
páginas
depto*
departamento
prof*
professor
profs*
professores
profa*
professora
profas
professoras
profª
professora
dra
doutora
drª
doutora
nº
número
vol.
volume
tts
t t s
eua
estados unidos américa
lga.
lagoa
al.
alameda
art.
artigo
c.p.
caixa postal
ed.
edição
e.m.e.f.e.i.
emefei
e.m.e.i.
emei
eq.
equação
cp*
caixa postal
dr.
doutor
dr.a
doutora
dr.ª
doutora
cód.
código
sta.
santa
sto.
santo
abr.*
abril
côn.
cônego
méd.
médico
abrev.
abreviação
pto.
ponto
pts.
pontos
suj.
sujeito
ago*
agosto
fev*
fevereiro
dep.
deputado
pça*
praça
tels.
telefones
alm.
almirante
s.a.
sociedade anônima
eh
é
sr
senhor
etc
et cétera
sra
senhora
srª
senhora
ex.
exemplo
p.ex.
por exemplo
srta*
senhorita
srtª*
senhorita
fig*
figura
vc
você
jr*
júnior
vcs
vocês
ltda.*
limitada
vl
vila
pct
por cento
prof.a
professora
prof.ª
professora
sr.a
senhora
sr.ª
senhora
srt.a
senhorita
srt.ª
senhorita
universit
universitário
mín*
mínimo
máx*
máximo
esq.
esquerdo
mons.
monsenhor
a/c
aos cuidados
caixa
estr.
estrada
mto
muito
deps.
deputados
temp.
temperatura
aprox*
aproximadamente
obs.
observação
univ.
universidade
rod.
rodovia
hj
hoje
dptos*
departamentos
bco.
banco
sarg.
sargento
brig.
brigadeiro
c/.
com
pgto*
pagamento
jd.
jardim
vs.
versus
* a abreviação também pode terminar com ponto
Léxico do usuário - Arquivo USER.DAT¶
Além do léxico de abreviações padrão, existe um léxico editável pelo usuário. Trata-se do arquivo “user.dat” que é opcional e deve estar localizado no diretório de instalação do Texto Fala.
Na sua forma mais simples, as entradas deste arquivo consistem da abreviação seguida da sua forma expandida.
É possível especificar para qual idioma as substituições valem colocando os marcadores [LANGUAGE: PTBR] para o português do Brasil e [LANGUAGE:ES] para o espanhol latino-americano, antes das entradas correspondentes. Caso os marcadores não sejam utilizados, ou as entradas estejam antes do primeiro marcador usado, a substituição valerá para todos os idiomas disponíveis.
Exemplo:
[etc] [etcétera]
[LANGUAGE:PTBR]
[cx] [caixa]
[bd] [base de dados]
[LANGUAGE:ES]
[ej] [ejemplo]
[srl] [sociedad de responsabilidad limitada]
Abreviações especificadas como acima podem ou não ser seguidas de ponto no texto de entrada; caso o ponto exista, ele é mantido na expansão da abreviação. Por exemplo, a sentença “acesso do cx à bd. com erro.” será expandida para “acesso do caixa à base de dados. com erro.”, com o ponto mantido após a expansão “base de dados”.
Caso se deseje que o ponto da abreviação não seja mantido no texto expandido, deve-se usar a opção “/p” após a definição da abreviação e incluir o ponto na definição da mesma. Quando a opção “/p” é especificada, mas o ponto não é incluído na definição da abreviação, esta somente é reconhecida se o ponto não estiver presente no texto de entrada.
Exemplos:
[LANGUAGE:PTBR]
[tx.] [transmissor] /p
[tx] [taxa] /p
Neste caso, a sentença “um tx. de alta tx de transferência.” será expandida para “um transmissor de alta taxa de transferência.”
Caso uma abreviação especificada com a opção “/p” e terminada por ponto ocorra em final de sentença, é necessário incluir um ponto final adicional para indicar o término da sentença, separado do ponto da abreviação por um espaço. Exemplo: “ligue o tx. .” será expandido para “ligue o transmissor.”
Caso se queira tratar uma dada abreviação com e sem a presença do ponto, é necessário incluir as duas formas de tratamento no léxico, em linhas independentes.
Por padrão, não há distinção entre letras maiúsculas e minúsculas nas abreviações especificadas no léxico do usuário. Caso se deseje fazer essa distinção, a opção “/c” deve ser empregada.
Exemplos:
[LANGUAGE:PTBR]
[ap] [apartamento] /c
[Ap] [aparecida] /c
Neste caso, a sentença “maria Ap mora no ap dez” será expandida para “maria aparecida mora no apartamento dez”. Se desejado, as opções “/c” e “/p” podem ser usadas em conjunto para uma mesma abreviação, bastando especificar ambas em sequência, separadas por um espaço.
Na expansão de abreviações especificadas no léxico, somente devem ser usados caracteres alfabéticos e os caracteres de traço e espaço. Não são permitidos dígitos ou símbolos especiais.
Deve-se ter bastante cuidado com a inserção de entradas no arquivo user.dat, já que podem produzir-se efeitos colaterais impensados pelo usuário. Por exemplo, a inclusão de “PM” para ser substituído por “Policia Militar”, fará que o texto de entrada “recebi a mensagem às 9:00 PM” seja substituído por “recebi a mensagem às nove horas polícia militar”, significado totalmente diferente do esperado.
Uma entrada no arquivo user.dat consiste dos seguintes elementos: o termo a ser substituído entre colchetes, um tab, a substituição entre colchetes, um espaço e os parâmetros opcionais. Uma palavra isolada pode ser substituída por múltiplas palavras e vice-versa.
Exemplos:
[LANGUAGE:PTBR]
[dr] [doutor] /p
[sr] [senhor]
[sa] [sociedade anônima]
[New York] [nova iorque]
[LANGUAGE:ES]
[ej] [ejemplo]
[srl] [sociedad de responsabilidad limitada]
[bd] [base de datos]
[of course] [claro]
Parâmetros opcionais:
/c: usado para levar em conta a caixa das letras; o padrão (sem /c) é não diferenciar maiúsculas de minúsculas (ver explicação dada anteriormente).
/p: usado para consumir ou não o ponto que segue a abreviação (ver explicação dada anteriormente).
Rótulos ou Marcadores
- [LANGUAGE:PTBR]
Incluir antes das substituições que devem valer para o português do Brasil.
- [LANGUAGE:ES]
Incluir antes das substituições que devem valer para o espanhol da latino-americano.
Entradas para todos os idiomas: incluí-las antes dos rótulos.
É possível, ainda, criar sessões específicas no arquivo user.dat, contendo tabelas de substituição cujo uso pode ser habilitado ou desabilitado por meio do uso das tags SSML lexicon e lookup no texto de entrada. Mais detalhes a respeito do uso desse recurso podem ser encontrados em Interpretador SSML.