Protocol¶
The WebSocket API uses a set of messages to trigger the server’s speech recognition functions. The connection between client and server is established according to the default process used for this technology, in other words, by means of an HTTP handshake message sent by the client, indicating a connection upgrade to the WebSocket protocol. The server will answer the handshake and open a socket connection with the client. From that moment on, messages can be exchanged between the two endpoints.
The current WebSocket API version is 2.3. It comprises the following messages:
Message |
Description |
|---|---|
CREATE SESSION |
Creates a speech recognition session. To be sent by the client after establishing a WebSocket connection with the server. |
DEFINE GRAMMAR |
Loads and compiles a grammar that can later be used for recognition. |
START RECOGNITION |
Starts the recognition. Must be sent before starting to capture the client’s audio. Indicates the language model to be used by the server. Allows parameters to be defined for this recognition. |
INTERPRET TEXT |
Performs semantic interpretation of a text supplied by the client, using the indicated grammar, like the START RECOGNITION message. |
START INPUT TIMERS |
Starts the speech start and recognition timers. |
SET PARAMETERS |
Defines the parameters for the recognition session. Must be sent before the START RECOGNITION message. The parameters are valid for all recognitions in this session. |
GET PARAMETERS |
Returns the current value of the recognition session parameters. |
SEND AUDIO |
Transports an audio sample to be recognized. We recommend sending small samples to achieve recognition results as close as possible to real time results. |
CANCEL RECOGNITION |
Cancels recognition and discards partial results. |
RELEASE SESSION |
Closes the recognition session, releasing allocated resources. When receiving this message, the server closes the WebSocket connection. |
Message |
Description |
|---|---|
RESPONSE |
Server response to any message sent by the client, with the exception of the SEND AUDIO message, which is only sent in case of errors. |
RECOGNITION RESULT |
Recognition results of the received audio, which can be partial results or final results. |
START OF SPEECH |
Indicates that the server has detected the beginning of a speech segment in the audio samples received from the client. The client must continue sending audio samples to the server. |
END OF SPEECH |
Indicates that the server has detected the end of a speech segment in the audio samples, and will generate the final result of the recognition of this segment. |
The following diagram illustrates a message sequence used by the API for speech recognition. A detailed description of each message can be found in the section Message format.
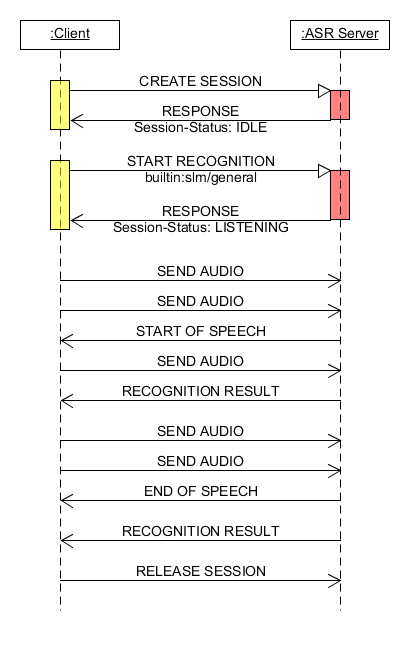
Fig. 11 WebSocket API usage scenario¶
The client application opens a WebSocket connection with the CPQD ASR server.
After the session is opened, the client must send a CREATE SESSION message to create a recognition session, exclusively allocated to that connection. The number of sessions that can be created depends on the number of available licenses.
To start recognition, the customer must send a START RECOGNITION message, informing the language model (LM) that is to be used, which can be a free speech model or grammar model.
The client must then start capturing the audio and send the audio stream in short blocks, e.g. 200 ms, using the SEND AUDIO message. The server will analyze the received audio samples continuously, identifying the speech segments.
When the server detects the start of the speech, the START OF SPEECH message will be sent to the client. While processing the speech segment, the server can send partial recognition results using the RECOGNITION RESULT message.
When the server detects the end of the speech, the END OF SPEECH message will be sent to the client. No new samples must be sent by the client after receiving this message. The server will generate the end result of the recognition for this segment, sending the RECOGNITION RESULT message again.
If the audio stream ends before receiving the END OF SPEECH message, the client must send the last SEND AUDIO message, with the LastPacket header defined as true. This will cause the server to close the recognition session and generate the final result for the speech segment.
If the client should wish to perform a new recognition, they must send the START RECOGNITION message again.
The communication with the server can then be closed using the RELEASE SESSION message, or by closing the WebSocket connection.