Continuous Mode¶
The WebSocket API allows the use of continuous mode in speech recognition, and the audio can be sent in real time. Further information in the section Continuous Mode.
An example of a request is shown below. To use continuous mode, the license must be valid, and the parameter decoder.continuousMode=true.
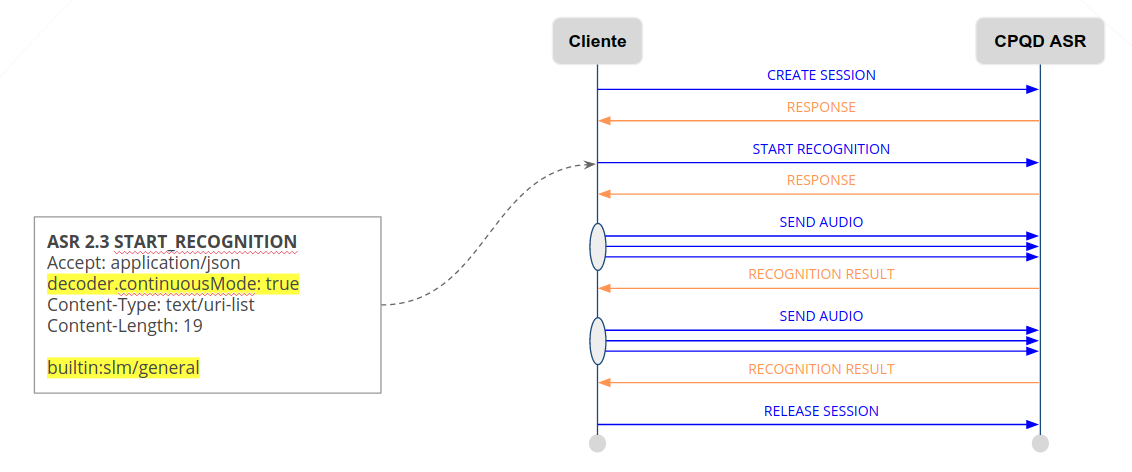
The result of each speech segment is returned as soon as it is processed.
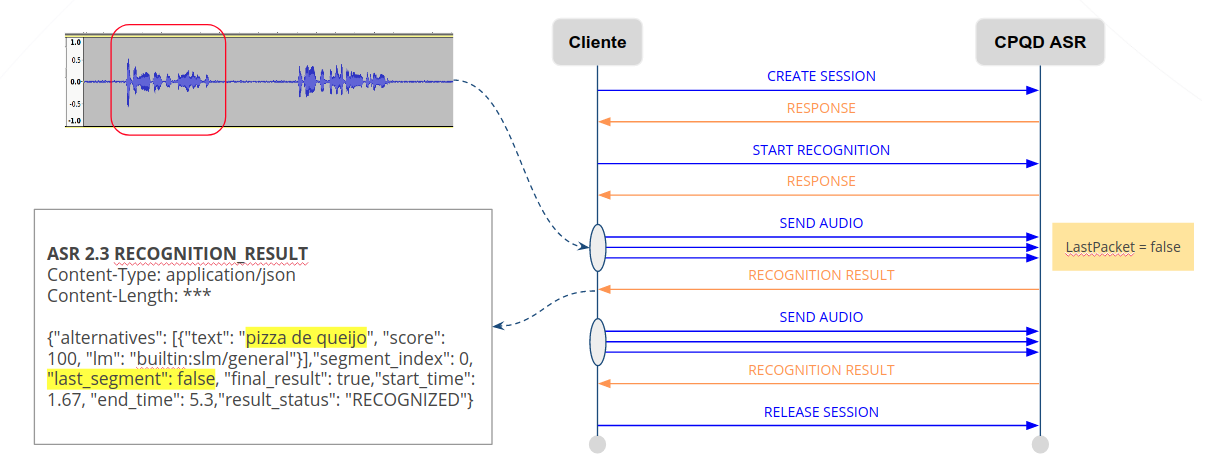
Audio streaming can be ended by configuring the ‘LastPacket=true’ parameter. The result of the last speech segment is returned with the parameter ‘last_segment=true’:
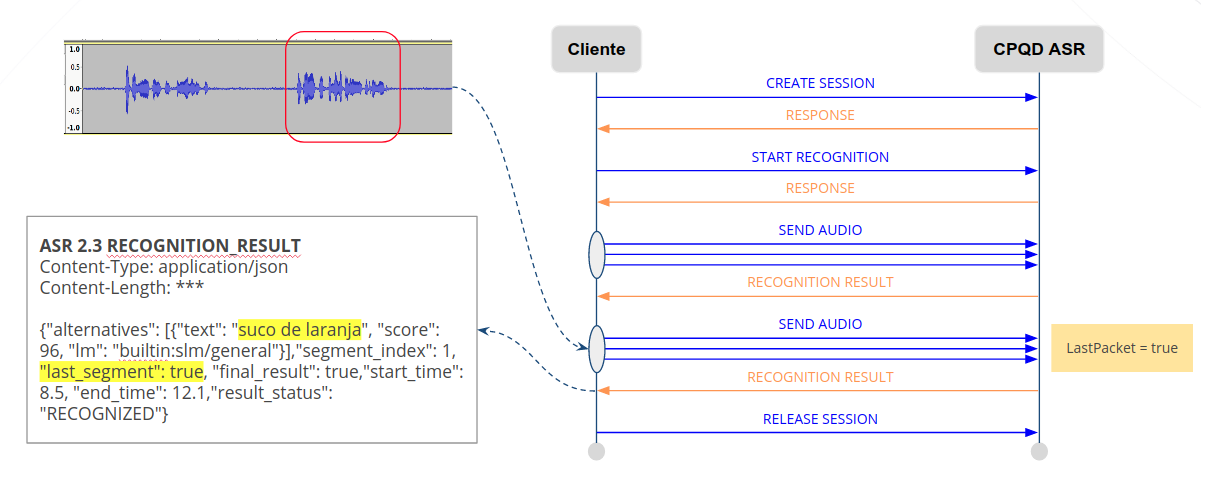
The summary of the continuous mode flow in the WebSocket API is as follows:
The client opens a WebSocket connection with the ASR server and sends a CREATE SESSION message.
The ASR server sends a RESPONSE message to signal success.
The client starts recognition using the START RECOGNITION message, and informs the language model (usually a free speech model) and the parameter “decoder.continuousMode = true”.
The ASR server sends a RESPONSE message to signal success.
The client starts capturing the audio and sends it in blocks, using the SEND AUDIO message.
The ASR server processes the recognition of each block, and as soon as there is a result, sends it with the RECOGNITION RESULT message.
The client stops the audio stream by sending the SEND AUDIO message with the parameter “LastPacket = true”.
The ASR server processes the remaining recognition and sends the last result through the RECOGNITION RESULT message with the parameter “last_segment = true.”
The client can end the session with the message RELEASE SESSION or begin another recognition session with the message START RECOGNITION.