Continuous Mode¶
Speech recognition can be done in two different ways: ‘simple mode’ or ‘continuous mode’.
Simple mode is the default operational mode (decoder.continuousMode=false). Recognition is performed only on the first speech segment identified in the audio, in other words, all audio after an interval of silence longer than the value of the endpointer.waitEnd parameter is discarded (see the following figure).
This mode is usually used in dialog applications, where a short answer to a question from the application is expected. It is not the appropriate option for transcribing long stretches of audio with several sentences. It can be used with free speech grammars.
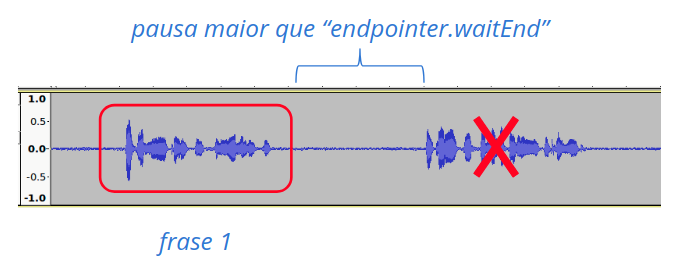
Fig. 9 Simple mode recognition¶
When running in continuous mode, recognition is performed for all the speech segments in the input audio. The recognition process usually continues until the end of the audio (see the following figure).
As a rule, this mode is used with the free speech model, in applications used to transcribe long audio segments, with lots of sentences and pausing, with real time recognition or not.
Warning
To use continuous mode, you must have a valid license and the parameter decoder.continuousMode=true.
Continuous mode is only available in the WebSocket and REST APIs, and has a very specific operational dynamic. For more information, please see the sections on continuous mode in the WebSocket API and REST API.
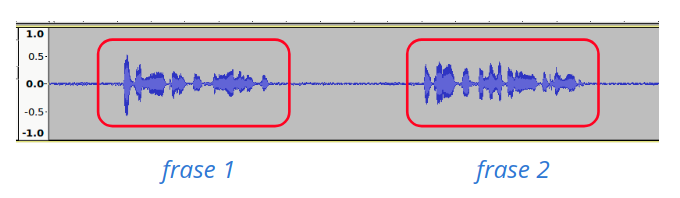
Fig. 10 Continuous mode recognition¶