Integration with the ASR¶
To develop an application with speech recognition, one of the steps is to establish communication with the CPQD ASR and be able to use its features. Fig. 8 depicts the overall logical structure of the system components, including the different ways to integrate with the application.
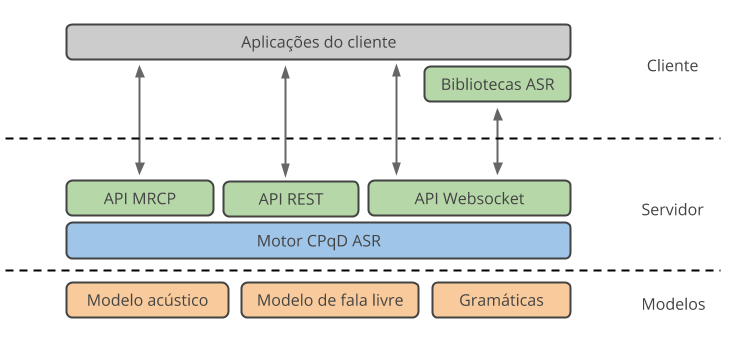
Fig. 8 CPQD ASR Components¶
Developers can deploy this integration using the provided ASR API directly, developing all the needed code in compliance with the protocol defined by the selected API. Available ASR APIs are:
WebSocket API
REST API
MRCP API
The API you decide to use depends on the context of the application. The following table presents a brief comparison of these APIs, and their ASR features:
Feature |
WebSocket |
REST |
MRCP v1/v2 |
|---|---|---|---|
Free speech recognition |
X |
X |
X |
Recognition with grammars |
X |
X |
X |
N-best list |
X |
X |
X |
Confidence score |
X |
X |
X |
Interpretation |
X |
X |
X |
Real time recognition |
X |
X |
|
Speech start and stop events |
X |
X |
|
Intermediate results |
X |
||
Continuous mode recognition |
X |
(1) |
*(1) Continuous mode recognition using the ASR REST API is possible, but it is not highly recommended. The size of the audio is restricted, since it needs to be totally loaded into memory, and the transcription can only be viewed after the audio has been completely recognized. In comparison, the WebSocket API recognizes long segments of audio in real time, and the transcript is displayed simultaneously as the recognition takes place.
Using client libraries¶
To simplify integration with the CPQD ASR, a set of open-source client libraries are provided, with several different programming languages. These libraries use the WebSocket API, but allow interaction with the ASR on a much higher level. They can be used directly or be modified by developers to meet the needs of the application.
The following client libraries are currently available:
Using the MRCP API¶
The MRCP is a standard protocol adopted by the market, and is frequently used to provide audio, synthesis and speech recognition features to telecommunication systems, especially IVR. based dialog applications.
The MRCP API is usually the option of choice when developers use an IVR that comes with an MRCP integration, such as Asterisk).
For more information regarding the MRCP integration, please see the CPQD MRCP <https://speechweb.cpqd.com.br/mrcp/docs/2.0>`_ Server Guide.
Using the WebSocket API¶
The ASR WebSocket API is the most complete interface, since it allows all the CPQD ASR features to be used. It uses the WebSocket protocol and allows dedicated bidirectional client-server communication, with low latency and insignificant overhead for audio streaming.
This API is usually used when the application wants to recognize the speech as soon as the audio is captured (what we call real time recognition). It allows long stretches of audio to be recognized, provided the audio is sent with a sampling rate compatible with the ASR’s recognition speed. It allows continuous mode recognition, intermediate results, and speech start and stop events. It is the most common form of integration for applications on servers or mobile devices.
Developers wishing to deploy communication using this API must check the WebSocket API section.
Using the REST API¶
The ASR REST API is the most simple and the easiest interface to use, however, it provides less ASR features. It uses the HTTP protocol and allows synchronous and stateless communication between the application and the CPQD ASR.
This API is indicated for applications that already have short audios, of around 1 minute each, recorded. By default, it supports audios of up to 15 minutes. It does not allow receiving intermediate recognition results, nor does it perform real time recognition. It is a simple form for running tests or recognition demos.
Developers wishing to deploy communication using this API must check the ref:api-rest section.
Since it is an API that only uses HTTP requests, we can perform simple speech recognition tasks, using different programming languages, especially with the support of libraries.
For example, in Python, we can use the requests library to recognize the file audio/teste.wav using the general free speech model builtin:slm/general:
import requests
url = "http://127.0.0.1:8025/asr-server/rest/recognize"
params = {"lm":"builtin:slm/general"}
headers = {"Content-Type":"audio/wav"}
audio = open("audio/teste.wav", "rb").read()
r = requests.post(url, params=params, headers=headers, data=audio)
print(r.content.decode("UTF-8"))
The ‘requests’ library can be installed running:
pip install requests
Using Java, we can run the same recognition using Apache HttpClient Fluent API <https://hc.apache.org/httpcomponents-client-ga/tutorial/html/fluent.html>`_:
import java.io.File;
import org.apache.http.client.fluent.Request;
import org.apache.http.entity.ContentType;
public class RecognitionTest {
public static void main(String[] args) throws Exception {
String response = Request.Post("http://127.0.0.1:8025/asr-server/rest/recognize?lm=builtin:slm/general")
.bodyFile(new File("audio/teste.wav"), ContentType.create("audio/wav"))
.execute().returnContent().asString();
System.out.println(response);
}
}
The HttpClient component can be added to the project using Maven, for example:
<dependencies>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.6</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>fluent-hc</artifactId>
<version>4.5.6</version>
</dependency>
</dependencies>
There are also ready-made tools that can be used for tests. For the examples in this guide, we will use the cURL tool, available in Linux. With this tool, we can perform the same recognition, with the following command:
curl --header "Content-Type: audio/wav" \
--data-binary @audio/teste.wav
http://127.0.0.1:8025/asr-server/rest/recognize?lm=builtin:slm/general