Modo Assíncrono¶
Para aplicar o modo assíncrono utilize o método StreamingRecognizeRequest. Este modo é mais indicado para reconhecimento de fala em tempo real.
A API GRPC permite o uso do modo contínuo no reconhecimento de fala em ambos métodos de serviço (assincrono e síncrono).
Para usar o modo contínuo, a licença deve estar liberada e deve-se definir o parâmetro config.continuous_mode=true.
Para mais informações sobre o modo contínuo veja mais em Modo contínuo.
O uso do modo contínuo é apresentado no exemplo de requisição abaixo.
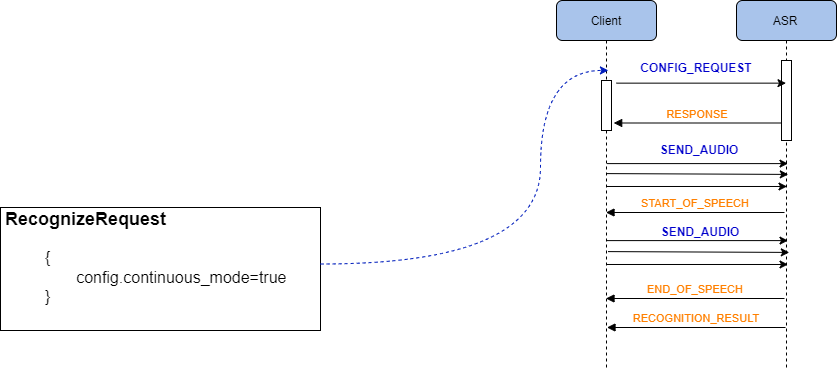
O resultado do reconhecimento de cada segmento de fala é retornado a medida em que é processado:
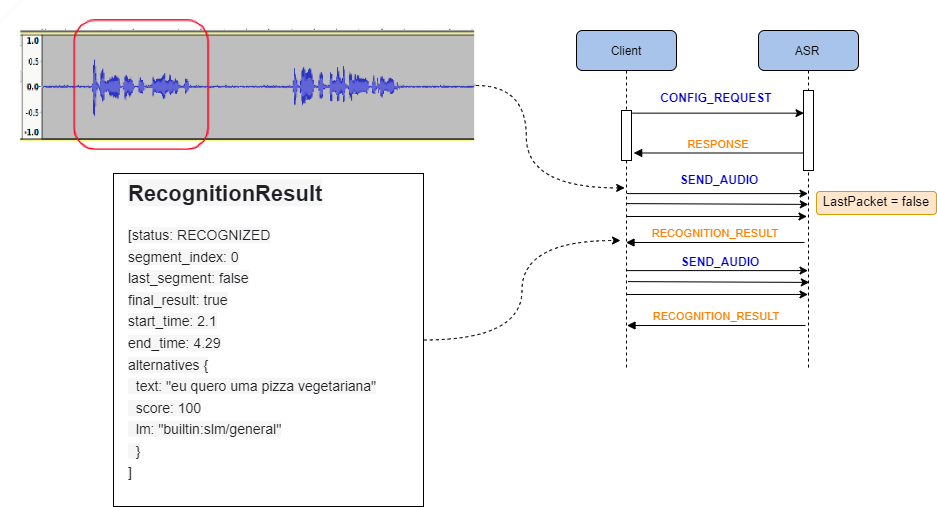
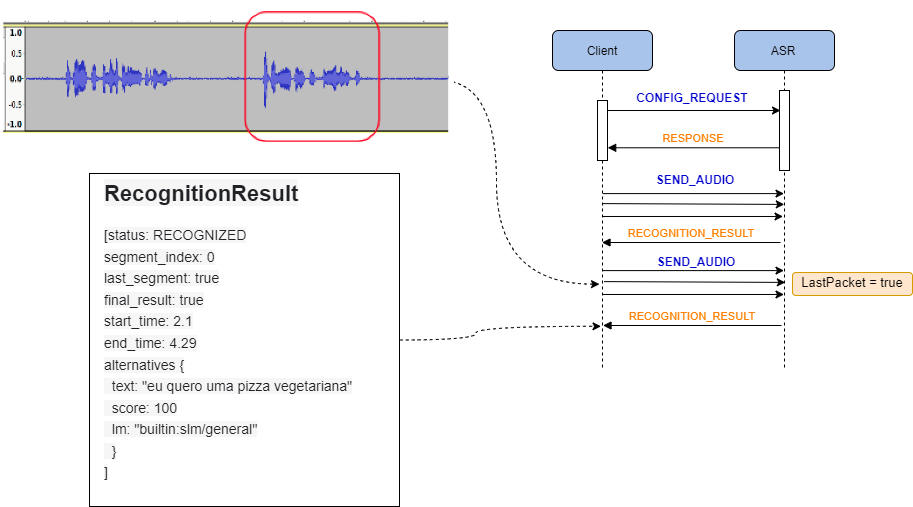
O envio do áudio pode ser finalizado definindo o parâmetro “LastPacket=true”. O resultado do último segmento de fala é retornado com parâmetro “last_segment=true”
O resumo do fluxo do modo contínuo na API GRPC é apresentado abaixo:
A aplicação cliente abre um canal GRPC com o Servidor ASR;
Após a abertura, o cliente deve enviar uma requisição de configuração (CONFIG_REQUEST) para iniciar uma sessão de reconhecimento, que é alocada exclusivamente para aquela conexão. Esta requisição deve ter um campo config especificado no arquivo .proto. A quantidade de sessões que podem ser criadas depende da quantidade de licenças disponíveis no servidor;
O cliente deve iniciar a captura do áudio e enviar o stream de áudio em blocos de pequena duração, por exemplo, 200ms, através da requisição de envio de audio (SEND_AUDIO). Esta requisição deve ter um campo media do tipo array de bytes do audio. Se usado o serviço StreamingRecognize, a requisição também deve conter o campo last_packet. Este campo indica o fim do envio de audios. O servidor irá analisar continuamente as amostras de áudio recebidas, identificando o segmento de fala;
Quando o servidor detectar o início da fala, o mesmo enviará uma resposta com um evento START OF SPEECH. Durante o processamento do segmento de fala, o servidor poderá enviar resultados parciais do reconhecimento através da resposta PARTIAL RECOGNITION RESULT, ou seja, final_result = false;
Quando o servidor detectar o fim da fala, a resposta com um evento END OF SPEECH será enviada. O servidor irá gerar o resultado final do reconhecimento para esse segmento, enviando novamente uma resposta RECOGNITION RESULT; Se nesta resposta o campo last_segment for igual a TRUE, o cliente deve encerrar a chamada.
Para realizar um novo reconhecimento, o cliente deverá enviar novamente uma requisição de configuração;
A comunicação com o servidor é encerrada quando o cliente encerrar o canal.