Modo contínuo¶
A API REST permite o uso do modo contínuo no reconhecimento de fala, mas o áudio completo deve ser enviado através de uma única requisição HTTP. Para usar o modo contínuo, a licença deve estar liberada e deve-se definir o parâmetro decoder.continuousMode=true (válido para ambiente on premise) ou decoder-continuousMode=true (válido para ambiente SaaS do CPQD e on premise). Outras informações na seção Modo contínuo.
Um exemplo de requisição usando o comando curl do Linux, válido para ambiente on premise, é mostrado abaixo:
curl --header "Content-Type: audio/wav" \
--header "decoder.continuousMode: true" \
--data-binary @<arquivo wav> \
https://<HOST>:8025/asr/rest/v3/recognize
Um exemplo de requisição usando o comando curl do Linux, válido para ambiente SaaS e on premise, é mostrado abaixo:
curl --header "Content-Type: audio/wav" \
--header "decoder-continuousMode: true" \
--data-binary @<arquivo wav> \
https://<HOST>:8025/asr/rest/v3/recognize
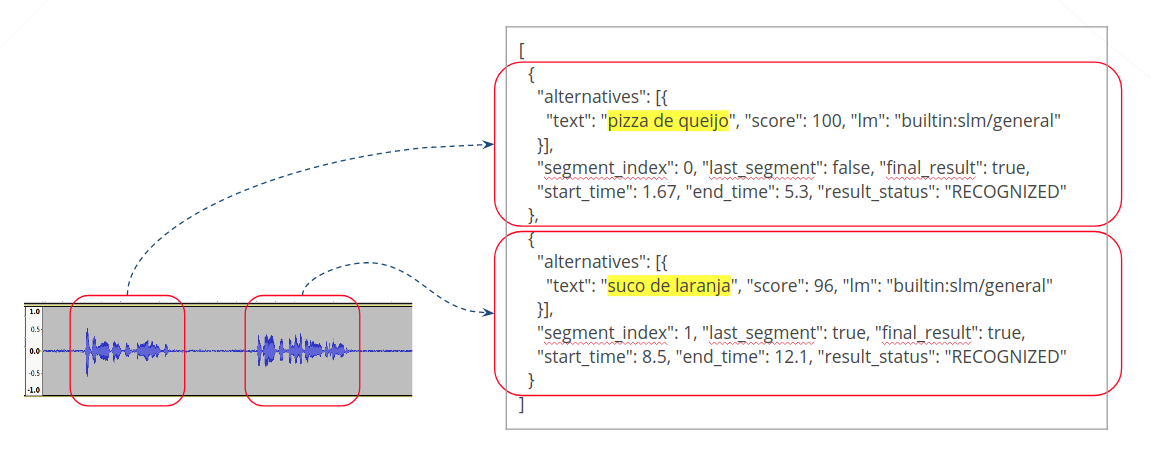
Apenas depois do envio do áudio, o reconhecimento é finalizado e o resultado completo é retornado. O resultado do reconhecimento segue o padrão da API, mas contém a transcrição de todos os segmentos de fala do áudio, como mostrado no exemplo seguinte (campos foram omitidos para simplificar):