Modo assíncrono¶
A API WebSocket permite o uso do modo contínuo no reconhecimento de fala e o áudio pode ser enviado em tempo real. Outras informações na seção Modo contínuo.
Um exemplo de requisição é mostrado abaixo. Para usar o modo contínuo, a licença deve estar liberada e deve-se definir o parâmetro decoder.continuousMode=true.
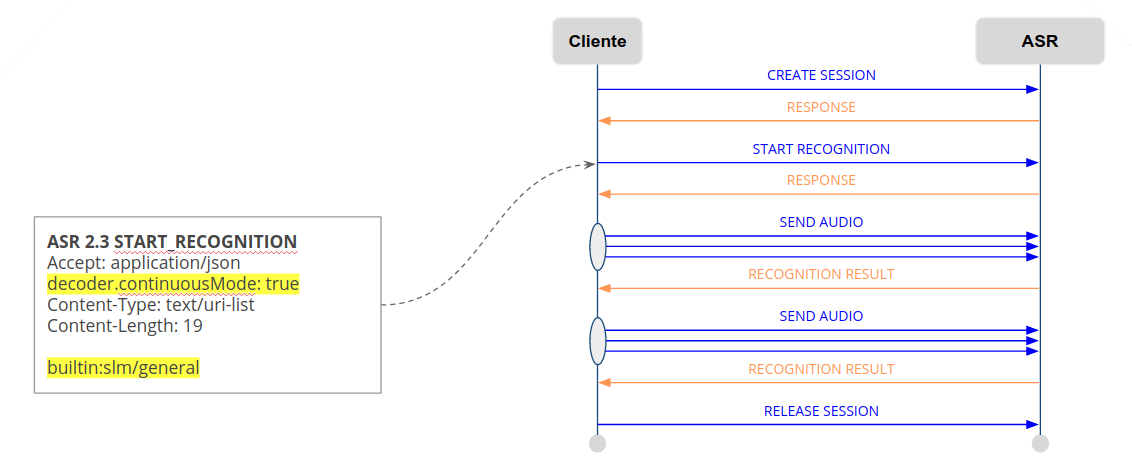
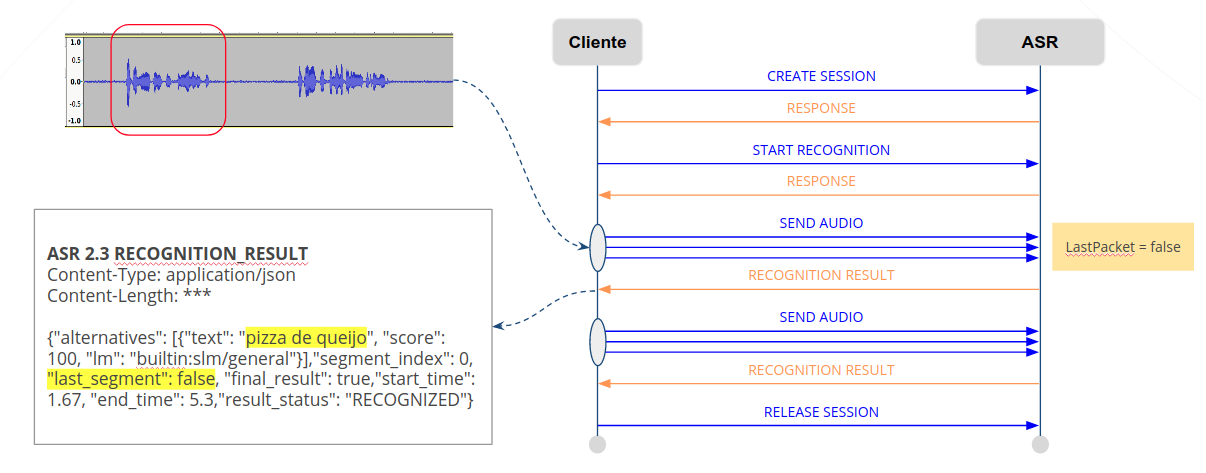
O resultado do reconhecimento de cada segmento de fala é retornado a medida em que é processado:
O envio do áudio pode ser finalizado definindo o parâmetro “LastPacket=true”. O resultado do último segmento de fala é retornado com parâmetro “last_segment=true”:
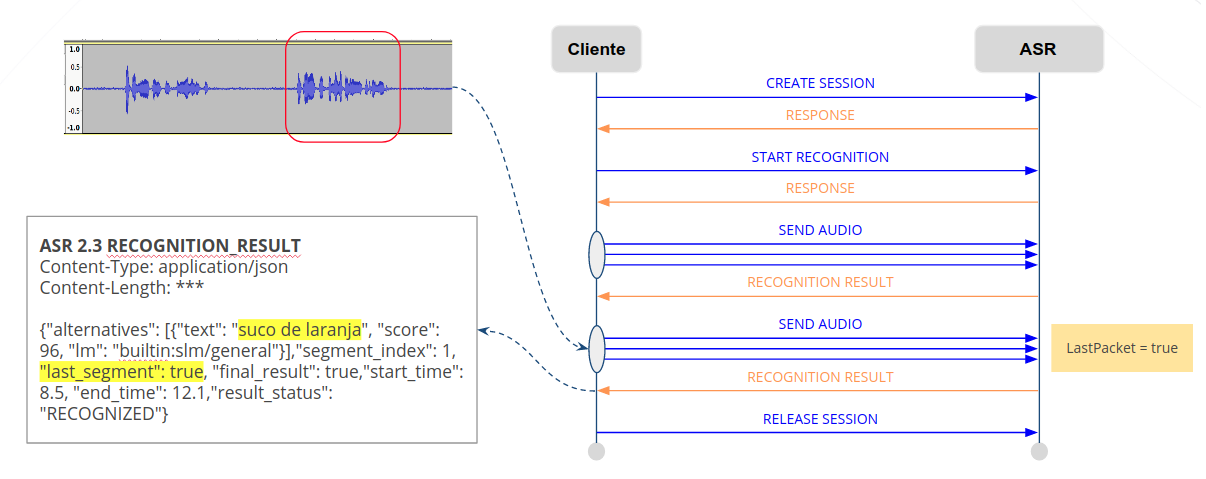
O resumo do fluxo do modo contínuo na API WebSocket é apresentado abaixo:
O cliente abre uma conexão WebSocket com o Servidor ASR e envia a mensagem CREATE SESSION.
O servidor ASR indica sucesso através da mensagem RESPONSE.
O cliente inicia o reconhecimento enviando START RECOGNITION, e informa o modelo de língua (normalmente um modelo de fala livre) e o parâmetro “decoder.continuousMode = true”.
O servidor ASR indica sucesso através da mensagem RESPONSE.
O cliente inicia a captura do áudio e envia em blocos através da mensagem SEND AUDIO.
O servidor ASR realiza o reconhecimento de cada bloco e quando possui um resultado envia-o através da mensagem RECOGNITION RESULT.
O cliente finaliza o áudio enviando a mensagem SEND AUDIO com o parâmetro “LastPacket = true”.
O servidor ASR realiza o reconhecimento restante e envia o último resultado através da mensagem RECOGNITION RESULT com o parâmetro “last_segment = true”.
O cliente pode finalizar a sessão com a mensagem RELEASE SESSION ou iniciar outro reconhecimento com a mensagem START RECOGNITION.