Trabalhando com léxicos¶
Este capítulo descreve o mecanismo através do qual pronúncias são atribuídas às palavras de uma gramática durante a compilação; ele descreve ainda como os usuários podem determinar quais pronúncias estão sendo atribuídas a quais palavras, e como elas podem ser personalizadas.
Léxicos e pronúncias das palavras¶
Um léxico é um dicionário que mapeia palavras em uma ou mais pronúncias. Cada pronúncia é uma sequência de unidades sonoras básicas, denominadas fones, e está associada a uma probabilidade de ocorrência, que quantifica as chances de o usuário pronunciar a palavra daquela maneira. Quando uma gramática é compilada, o compilador deve determinar uma lista de pronúncias para cada palavra na gramática, juntamente com suas probabilidades correspondentes. Para tanto, o compilador realiza uma série de consultas, envolvendo três tipos de recursos capazes de gerar transcrições fonéticas:
Léxicos do usuário: um arquivo de gramática pode referenciar um ou mais léxicos, contendo pronúncias definidas pelo usuário para palavras na gramática (SRGS, seção 4.10). No formato ABNF, isso é feito através da declaração lexicon no cabeçalho da gramática; no formato XML, utiliza-se o elemento <lexicon>.
Léxico do modelo acústico: um pacote de modelo acústico pode incluir um léxico correspondente, com pronúncias para palavras na língua alvo do modelo.
Transcrição automática: se alguma palavra não constar nem em nenhum léxico definido pelo usuário, nem no léxico do modelo acústico, uma ferramenta de conversão grafema-fonema (grapheme to phoneme, G2P) automática será invocada para atribuir uma transcrição fonética à palavra.
O procedimento de consulta respeita a seguinte ordem de prioridade:
Léxicos definidos pelo usuário, segundo a ordem de inclusão no arquivo fonte da gramática. Ou seja, quando múltiplas declarações lexicon são encontradas em uma gramática ABNF (ou múltiplos elementos <lexicon>, em uma gramática XML), os léxicos são consultados do primeiro a aparecer no arquivo de gramática em sequência até o último.
O léxico do modelo acústico, se o modelo possuir algum.
Ferramenta G2P automática.
Enquanto procura pela lista de pronúncias a ser associada a cada palavra da gramática, os léxicos são consultados na ordem especificada acima; no momento em que um deles apresenta pelo menos uma pronúncia para a palavra atual, o processo de consulta é interrompido para aquela palavra, e a lista recém-encontrada é utilizada. Note que isso implica que a presença de uma palavra em um léxico de prioridade mais alta anula o efeito da presença dessas palavras em léxicos de prioridade inferior. Assim sendo, se o usuário deseja acrescentar uma ou mais pronúncias àquelas já disponíveis no léxico do modelo acústico para uma dada palavra, é necessário copiar tais pronúncias para o léxico do usuário, e então acrescentar as pronúncias desejadas. Caso alguma pronúncia não seja copiada para o léxico do usuário, ela não será mais aceita no reconhecimento; portanto, é possível remover pronúncias para uma dada palavra. É importante atentar-se para esse fato, a fim de evitar a perda indesejada de pronúncias.
A seção Criando léxicos do usuário apresenta mais detalhes sobre os léxicos definidos pelo usuário. Quando uma palavra não está presente em nenhum léxico, a ferramenta G2P automática é invocada; é possível saber a saída desta ferramenta para qualquer palavra; o procedimento para tanto está descrito na seção Avaliando pronúncias de palavras.
Criando léxicos do usuário¶
Durante a criação de uma gramática, pode ser necessário configurar manualmente as pronúncias a serem aceitas para certas palavras. Isso é tipicamente realizado para acomodar irregularidades no mapeamento grafema-fonema da língua alvo que podem levar à ausência da pronúncia correta de uma palavra nos léxicos disponíveis; exemplos de tais irregularidades incluem palavras estrangeiras, nomes de marcas, entre outros.
Um léxico do usuário em formato textual é um arquivo de texto, usualmente salvo com o nome lexicon.txt, separado em linhas tais que cada uma contenha três campos separadas pelo caractere «tab»:
A palavra.
A probabilidade de pronúncia (opcional).
A pronúncia, representada como uma sequência de fones separados por espaço.
Abaixo encontra-se um exemplo de uma linha retirada de um léxico textual para o Português Brasileiro, correspondente a um léxico com probabilidades de pronúncia (caracteres «tab» são representados como 8 espaços).
carro 1.0 kk aa rx uc
Probabilidades de pronúncia são opcionais; assim, a linha abaixo é válida em um léxico textual sem probabilidades de pronúncia:
carro kk aa rx uc
A presença de probabilidades de pronúncia é configurada no nível do arquivo; ou
seja, linhas contendo e linhas não contendo probabilidades de pronúncia não
podem aparecer no mesmo arquivo. Probabilidades de pronúncia devem ser tais
que 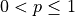 , mas sua soma não necessita ser unitária para cada
palavra; as probabilidades de pronúncia são adequadamente normalizadas durante
o processo de compilação. Em um léxico sem probabilidades de pronúncia,
a ocorrência de cada pronúncia no áudio de entrada é considerada igualmente
provável.
, mas sua soma não necessita ser unitária para cada
palavra; as probabilidades de pronúncia são adequadamente normalizadas durante
o processo de compilação. Em um léxico sem probabilidades de pronúncia,
a ocorrência de cada pronúncia no áudio de entrada é considerada igualmente
provável.
Os fones permitidos no campo de pronúncia variam conforme a língua alvo.
A ferramenta grammar-g2p, descrita na seção
Avaliando pronúncias de palavras,
é útil na compreensão da pronúncia de cada fone; essa ferramenta pode ser
utilizada para consultar a transcrição de palavras conhecidas e, a partir
delas, perceber como os fones são empregados na transcrição fonética.
Em arquivos de léxicos, espaços em branco que não sejam «tab» podem ocorrer em cada campo; nesse caso, espaços em branco no início e no final do campo são descartados, e múltiplos caracteres de espaço em sequência são considerados como um único espaço (ou seja, » palavra » é o mesmo «palavra»).
Suponha que haja um arquivo grammar.gram, contendo alguma gramática em formato ABNF. Pode-se adicionar um léxico textual lexicon.txt à gramática por meio da declaração lexicon no cabeçalho da gramática.
#ABNF 1.0 UTF-8;
lexicon <lexicon.txt>;
// Corpo da gramática
A URI do léxico, que aparece entre colchetes angulares, pode também ser um caminho absoluto ou relativo para um arquivo fora do diretório atual. Links para páginas da Web (por exemplo, links HTTP ou FTP) também são suportados. São permitidos múltiplos léxicos, blembrando-se que o procedimento descrito na seção Léxicos e pronúncias das palavras é aplicado durante a consulta de palavras.
#ABNF 1.0 UTF-8;
lexicon <lexicon1.txt>;
lexicon <../lexicon2.txt>;
lexicon </home/user/grammars/lexicon3.txt>;
// Corpo da gramática
Léxicos podem ser incluídos em gramáticas XML por meio do elemento <lexicon>.
<grammar xmlns="http://www.w3.org/2001/06/grammar"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2001/06/grammar
http://www.w3.org/TR/speech-grammar/grammar.xsd"
xml:lang="en" version="1.0">
<lexicon uri="lexicon.txt">
<!-- Corpo da gramática -->
Léxicos podem ser convertidos para um formato binário, para que sejam carregados mais rapidamente; esse procedimento está descrito na seção Trabalhando com léxicos binários. Por convenção, léxicos binários são salvos com uma extensão .bin. Por padrão, um léxico do usuário com extensão .txt é interpretado como um léxico textual sem probabilidades de pronúncia, e um léxico com extensão .bin é interpretado como um léxico binário (léxicos binários sempre possuem probabilidades de pronúncia, mesmo quando se originam a partir de léxicos textuais sem probabilidades). Esse comportamento pode ser alterado acrescentando-se um media type à URI do léxico de acordo com a tabela abaixo.
Tipo do léxico |
Media type |
|---|---|
Textual, sem probabilidades de pronúncia |
lexicon/text |
Textual, com probabilidades de pronúncia |
lexicon/text+probs |
Binário |
lexicon/bin |
Abaixo encontra-se um exemplo de como o media type pode ser incluído na URI dos léxicos.
#ABNF 1.0 UTF-8;
lexicon <lexicon1>~<lexicon/text>;
lexicon <../lexicon2.txt>~<lexicon/text+probs>;
lexicon </home/user/grammars/lexicon3.xyz>~<lexicon/bin>;
// Corpo da gramática
Léxicos em gramáticas externas¶
É importante compreender o comportamento do compilador de gramáticas com respeito a léxicos quando um arquivo de gramática contém uma referência a outro arquivo de gramática. Considere duas gramáticas a.gram e b.gram, representadas abaixo. O conteúdo dos arquivo lexicon_a.txt e lexicon_b.txt não é relevante.
a.gram |
b.gram |
|---|---|
#ABNF 1.0 UTF-8;
lexicon <lexicon_a.txt>;
root $root;
$root = reference to $<b.gram>;
|
#ABNF 1.0 UTF-8;
lexicon <lexicon_b.txt>;
root $root;
$root = this is grammar b;
|
Suponha ainda que a gramática a.gram será compilada.
$ grammar-compile a.gram
Neste caso, apenas o arquivo lexicon_a.txt será processado; o arquivo lexicon_b.txt não será processado. Isso ocorre porque, quando uma gramática é compilada, apenas léxicos referenciados diretamente na gramática são incluídos; léxicos referenciados em gramáticas externas referenciadas pela gramática sendo compilada são ignorados. Assim, se se deseja que o arquivo lexicon_b.txt seja incluído, a referência a ele deve ser movida para o arquivo a.gram, como mostrado na tabela abaixo.
a.gram |
b.gram |
|---|---|
#ABNF 1.0 UTF-8;
lexicon <lexicon_a.txt>;
lexicon <lexicon_b.txt>;
root $root;
$root = reference to $<b.gram>;
|
#ABNF 1.0 UTF-8;
// The line below doesn’t need
// to be commented, since
// the reference is ignored.
// lexicon <lexicon_b.txt>;
root $root;
$root = this is grammar b;
|
Esse comportamento tem origem no fato de que a versão atual da biblioteca de ASR não suporta pronúncias específicas à gramática. Ou seja: não é possível alterar a pronúncia de uma palavra em uma gramática externa e, ao mesmo tempo, manter inalteradas as ocorrências da mesma palavra na gramática principal. Assim, quando uma gramática auxiliar é referenciada por uma gramática principal, você deve se assegurar de que todas as palavras presentes na gramática auxiliar estão presentes no léxico da gramática principal; se esse não for o caso, e a gramática auxiliar incluir um arquivo de léxico, copie a linha que referencia esse léxico para a gramática principal. Não é necessário remover a referência da gramática auxiliar, pois ela será ignorada.
Trabalhando com léxicos binários¶
Caso se esteja utilizando um léxico muito grande, pode ser que o tempo necessário para compilar gramáticas que o referenciem fique significativamente alto. Nesse caso, é possível compilar léxicos textuais e gerar léxicos binários (e vice-versa). Em relação a seu arquivo texto correspondente, um léxico binário é tipicamente maior, mas ele leva menos tempo para ser carregado no momento da compilação da gramática em que ele é referenciado. É importante notar que, quer os léxicos referenciados por uma gramática sejam binários ou textuais, a gramática compilada resultante é exatamente a mesma.
Para a conversão entre formatos de léxico, a ferramenta lexicon-convert deve
ser utilizada. A ferramenta é chamada com dois parâmetros: uma URI
especificando o léxico de entrada, e outra especificando o léxico de saída.
Veja a seguir um exemplo de criação de um léxico binário a partir de um léxico
textual.
$ lexicon-convert lexicon.txt lexicon.bin
Em conformidade às convenções adotadas na seção Criando léxicos do usuário, o arquivo lexicon.txt é interpretado como um léxico sem probabilidades de repetição. Se o léxico possui probabilidades, acrescente um media type à URI do léxico de entrada ao invocar a ferramenta.
$ lexicon-convert "<lexicon.txt>~<lexicon/text+probs>" lexicon.bin
A conversão do formato binário para o textual é análoga.
$ lexicon-convert lexicon.bin lexicon.txt
$ # Ou, equivalentemente
$ lexicon-convert lexicon.bin "<lexicon.txt>~<lexicon/text>"
$ lexicon-convert lexicon.bin "<lexicon.txt>~<lexicon/text+probs>"
Avaliando pronúncias de palavras¶
Com frequência, durante a criação de léxicos do usuário, é útil checar quais
pronúncias estão sendo atribuídas a uma dada palavra (ou a um conjunto de
palavras). Para essa finalidade, a biblioteca de ASR provê uma ferramenta
denominada grammar-g2p. Abaixo encontra-se um exemplo de como essa
ferramenta pode ser utilizada para consultar as pronúncias que estão sendo
atribuídas a algumas palavras em português. A saída da ferramenta é dada no
formato de um léxico com probabilidades de pronúncia:
$ grammar-g2p carro casa maçã
carro 1 kk aa rx uc
casa 1 kk aa zz ac
maçã 1 mm aa ss an
Por padrão, as pronúncias geradas pela ferramenta grammar-g2p são para o
Português do Brasil, independente do modelo acústico instalado. Outro idioma
pode ser definido, executando o comando grammar-g2p, com a opção --lang
e o identificador do idioma desejado. Os dois idiomas atualmente suportados são
Português do Brasil (pt-br) e Espanhol da América Latina (es). Por exemplo, no
caso do Espanhol:
$ grammar-g2p --lang=es cuatro siete uno
A ferramenta grammar-g2p é capaz de transcrever também palavras inventadas.
Essa funcionalidade é bastante útil nos casos em que se deseja obter a
pronúncia de uma palavra, mas não se está suficientemente familiarizado com
o conjunto de fones adotado pela biblioteca de ASR.
$ grammar-g2p tuíter gúgou merchandáizin
tuíter 1 tt uu ii tt ee rf
gúgou 1 gg uu gg oo uw
merchandáizin 1 mm ee rf sh an dd aa ij zz in