Conceitos¶
Cenários¶
Os cenários são rótulos utilizados para categorizar voiceprints e áudios. Os voiceprints de um cenário não devem ser utilizados em conjunto com voiceprints de outro cenário, ainda que sejam do mesmo usuário. A diferenciação entre cenários pode ocorrer por duas razões:
. Separação lógica, caso em que dois cenários utilizam o mesmo modelo de IA, mas deseja-se separá-los em cenários por conta de características do áudio de entrada ou por mera organização. Essa separação é útil quando existem requisitos específicos em cada cenário (e.g. quantidade de fala necessária, nível de relação sinal/ruído).
. É preciso utilizar modelos de IA diferentes, efetivamente tornando os voiceprints incompatíveis. Este caso pode ocorrer quando é preciso atuar em áudios de domínios diferentes (e.g. áudios de telefonia e áudios capturados por microfone em um computador) e existem modelos mais adequados para cada domínio.
O tamanho máximo do nome de cenário é de 64 caracteres. O cenário deve iniciar com letras, e os demais caracteres podem ser letras, números e sublinhas (_). As letras não podem estar acentuadas e é feita a distinção entre maiúsculas ou minúsculas.
O preenchimento obrigatório do campo scenario está presente nos métodos de enroll e verify.
Modos de captura¶
Os modos de captura especificam a forma como uma aplicação entregará áudio para a solução de biometria.
- BATCH
Neste modo os áudios são fornecidos como um ou mais arquivos. Cada arquivo é processado individualmente para extrair enunciados e então todos os enunciados são fornecidos para a operação biométrica. Na interface REST, arquivos correspondem a entradas multipart, enquanto que no gRPC cada arquivo é passado em mensagens AudioPayload. Este modo é ideal para cenários onde os arquivos já foram completamente capturados no momento em que a aplicação utilizará a biometria ou quando a transmissão em tempo real não é possível/desejável.
Somente o modo de operação SINGLE pode ser utilizado.
- STREAMING
Neste modo o áudio é fornecido como um fluxo único e contínuo, usualmente em tempo real. Disponível apenas pela interface gRPC, cada mensagem AudioPayload é considerada como um fragmento de áudio e a aplicação envia tais mensagens na medida que realiza a captura. A solução fornece sinalização de detecção de início e final de fala através de eventos.
Os modos de operação suportados são SINGLE, MULTI e CONTINUOUS, sendo que o cadastro biométrico sempre opera em SINGLE.
Áudios e enunciados¶
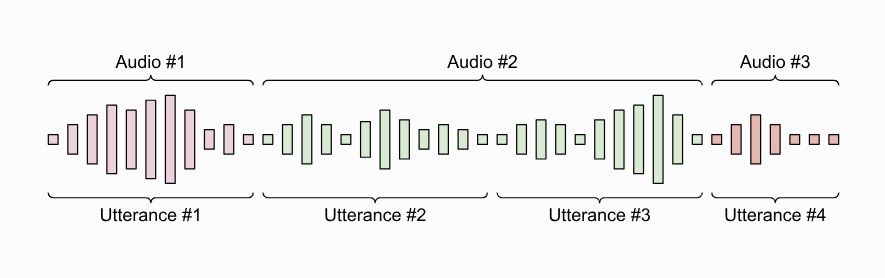
Do ponto de vista da solução de biometria, existem os conceitos de áudio e enunciado (do inglês utterance). O áudio é conteúdo enviado pela aplicação para a solução de biometria, via REST ou gRPC, através de um dos modos de captura disponíveis. Em alguns casos de uso, a quantidade de áudio pode ser substâncialmente grande, contendo várias frases ou mesmo uma conversa inteira do locutor.
Para otimizar as operações biométricas e a entrega dos resultados, a solução extrai uma ou mais porções de fala, denominadas de enunciados, utilizando um silêncio suficientemente longo como delimitador. Isso é essencial em operações de longa duração ou quando é esperada a entrega de resultados parciais.
Formato do áudio¶
O formato do áudio de entrada para chamadas de verificação e cadastro são especificados ao invocar as funções correspondentes. A especificação do formato é feita através de um dos valores abaixo:
auto: O formato é detectado automaticamente através do cabeçalho presente no conteúdo binário. É o valor padrão assumido pelo serviço quando nenhum valor for especificado na chamada da API. O serviço é capaz de detectar e utilizar os seguintes formatos:
FLAC
Waveform (cabeçalho RIFF) PCM Linear
Waveform (cabeçalho RIFF) uLaw e aLaw
MPEG-Layer 3 (MP3)
Ogg Vorbis
pcm/8000/16/mono: PCM Linear 8kHz 16bps Mono
pcm/16000/16/mono: PCM Linear 16kHz 16bps Mono
Internamente, o serviço utiliza áudios no formato pcm/8000/16/mono e pcm/16000/16/mono, logo todo áudio de entrada é convertido para um desses formatos. A conversão é realizada seguindo os seguintes critérios:
Se a taxa de amostragem do áudio de entrada for igual ou superior a
16kHz, é utilizado o formatopcm/16000/16/mono.Se a taxa de amostragem do áudio de entrada for inferior a
16kHz, é utilizado o formatopcm/8000/16/mono.