Arquitetura¶
O Texto Fala é composto por dois elementos principais: engine e servidor. A engine expõe as funcionalidades do produto através da interface de programação C/C++, interface utilizada quando integrando sua aplicação diretamente com a biblioteca dinâmica. O servidor é um serviço que integra-se com a engine e oferece as interfaces REST, WebSocket e gRPC. Mais detalhes são apresentados na seção Interfaces de integração.
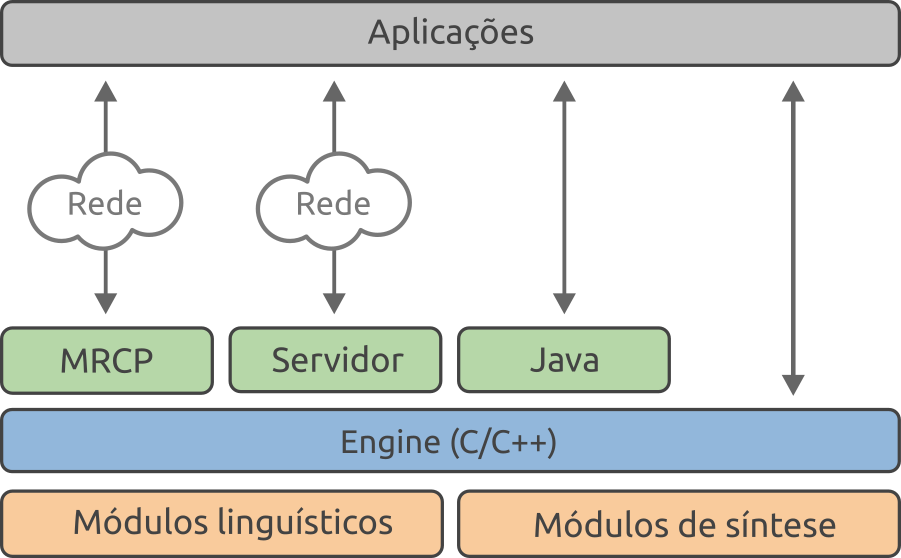
Componentes do Texto Fala e interfaces de integração¶
Engine¶
A engine é o componente responsável por processar e gerenciar as requisições de síntese de fala. O acesso às funcionalidades do Texto Fala, seja por aplicações ou pelas outras interfaces de integração, são feitas através da interface de programação C/C++ exposta pela engine.
Através do engine uma aplicação também pode configurar todos os parâmetros de configuração em tempo de execução, bem como fazer uso de SSML para sintetizar diálogos mais complexos ou que requeiram um controle mais refinado.
Quando utilizando a integração via biblioteca dinâmica, seja em C/C++ ou Java, é preciso inicializar o engine indicando onde o produto está instalado. Usualmente, a inicialização carrega os módulos e vozes instalados.
Módulo linguístico¶
O módulo linguístico é responsável pelo tratamento do texto que será vocalizado e por gerar informações que serão utilizadas pelo módulo de síntese na produção do sinal de fala. Cada idioma suportado pelo Texto Fala possui um módulo linguístico próprio, composto por uma biblioteca dinâmica (extensão .dll ou .so) e um arquivo de dados (extensão dat).
O tratamento do texto de entrada pelo módulo linguístico inclui a interpretação das tags SSML que eventualmente o texto possa conter, e a tokenização, normalização e conversão ortográfica-fonética deste texto.
O suporte à linguagem SSML v1.1 (Speech Synthesis Markup Language, https://www.w3.org/TR/speech-synthesis11/) oferecida pelo Texto Fala, permite que o usuário possa modificar a forma como o texto será falado. Para maiores detalhes sobre como utilizar o SSML com o Texto Fala, consulte a seção SSML.
Nas etapas de tokenização e normalização, o módulo linguístico converte por extenso certas ocorrências presentes no texto de entrada, como números, datas, quantias monetárias, abreviações e símbolos especiais. Como exemplo, o texto
Em 19/Ago/2016 às 9h, foram depositados R$15.000 na conta corrente da Dra. Denisse Oliveira.
é convertido para
em dezenove de agosto de dois mil e dezesseis às nove horas, foram depositados quinze mil reais na conta corrente da doutora denisse oliveira .
Existe um tratamento diferenciado de siglas, abreviações, números e outros termos específicos, de acordo com o contexto em que aparecem.
Na etapa de conversão ortográfica-fonética, o texto já normalizado é representado como uma sequência de fones que serão utilizados pelo módulo de síntese para gerar a fala sintetizada. Os fones são os sons básicos de um idioma a partir dos quais é possível gerar qualquer palavra da língua.
Atualmente o Texto Fala oferece as seis vozes listadas abaixo. Você pode conferir exemplos na seção Vozes disponíveis ou então testar o produto através da página de demonstração.
Rosana, Adriana e Carlos em o Português do Brasil;
Paola e Alejandro em o Espanhol Latino-Americano;
Melissa em o Inglês (EUA).
Módulo de síntese¶
O módulo de síntese é responsável por gerar o sinal de fala propriamente dito (áudio). Tal módulo usa como entrada as informações geradas pelo módulo linguístico e parâmetros especificados pelo usuário, como volume e ritmo. A partir dessas informações o módulo combina algoritmos e dados contidos nos arquivos de voz para gerar o sinal de fala.
Módulos de síntese são baseados em diferentes técnicas de síntese que apresentam diferentes vantagens e desvantagens. A escolha do módulo de síntese mais adequado para uma demanda, visando obter fala sintetizada mais natural, depende das características da aplicação e do cenário de uso no qual o sintetizador será utilizado.
Nota
O possui uma equipe técnica que pode efetuar avaliações junto ao cliente para definir as melhores opções. Entre em contato conosco para maiores informações.
Alguns dos aspectos mais comuns estão relacionados aos requisitos de hardware mínimos e a qualidade da fala sintezada. A versão atual do Texto Fala oferece três técnicas de síntese:
- high quality
Oferece a máxima qualidade de fala sintetizada consumindo menos poder computacional, em relação às outras técnicas. Vozes high-quality requerem mais memória, geralmente entre 300 MB e 1 GB. Essa é a opção mais adequada para uso em servidores ou clusters, onde o espaço em disco e memória não é um limitador e a quantidade de sínteses simultâneas é elevada.
- standard
Produz fala síntetizada de ótima qualidade com um requerimento de memória em torno de 100 MB para cada voz.
- compact
Possui o menor requerimento de memória, exigindo em média 10 MB por voz. Além disso, oferece boa qualidade fala sintetizada, apesar de requerer um poder computacional ligeiramente maior do que a versão high quality. Esta versão é adequada para uso em dispositivos embarcados ou em sistemas onde o espaço em disco é um limitador.
Todas as técnicas de síntese contam com todo o repertório de recursos oferecidos pelo Texto Fala, como síntese em tempo real, suporte ao SSML, chaveamento dinâmico de vozes, diferentes formatos do áudio de saída e efeitos sonoros.
Arquivos de voz¶
As vozes do Texto Fala são disponibilizadas através de arquivos com extensão .voice.
Quando disponível, podem existir arquivos complementares com extensão .question e .custom. Este último pode conter customizações da base de voz, fala expressiva, efeitos sonoros ou prompts. Customizações são aperfeiçoamentos na voz de forma que a fala sintetizada fique ainda mais natural e fluída quando pronunciando sentenças contendo terminologia específica do cenário de uso. Consulte a seção Serviços para maiores detalhes.