Working with lexicons¶
This chapter describes the mechanism by which pronunciations are added to a grammar during compilation. It also describes how users can define which pronunciations are assigned to which words, and how they can be customized.
Lexicons and word pronunciations¶
A lexicon is a dictionary that maps words to one or more pronunciation variants. Each pronunciation is a sequence of basic sonorous units, called phones, and is associated with an occurrence probability, which quantifies the odds of users pronouncing the word like that. When a grammar is compiled, the compiler must define a list of pronunciations for each word in the grammar, along with the corresponding probabilities. To do so, the compiler perform a series of queries, involving three types of features able to transcribe phonetic transcriptions:
User lexicons: a grammar file can reference one or more lexicons, containing user-defined pronunciations for words in the grammar (SRGS, section 4.10). In the ABNF format, this is done by means of the lexicon declaration in the grammar header; in the XML format, the <lexicon> element is used to accomplish this.
Acoustic model lexicon: an acoustic model package can include a corresponding lexicon, with pronunciations for the model’s target language.
Automatic transcription: If a word cannot be found in any user-defined lexicon, nor in the acoustic model, an automatic tool, grapheme to phoneme (G2P), is invoked to assign a phonetic transcription to that word.
The query procedure follows this priority sequence:
User-defined lexicons, according to the order in which they were included in the grammar source file. In other words, when multiple lexicon declarations are found in an ABNF grammar (or multiple <lexicon> elements, in an XML grammar), the lexicons are queried from the first grammar added to the grammar file, in sequence to the last one.
The acoustic model lexicon, if the model contains any.
Automatic G2P tool.
While looking for the list of pronunciations to be associated with each word in the grammar, the lexicons are queried in the order above described. The moment one of them presents at least one pronunciation for the current word, the query is interrupted for that word, and the newly-found list is used. Observe that this implies that the presence of a word in a lexicon with a higher priority annuls the effect of the presence of these words in lexicons with lower priority. Therefore, if the user wished to add one or more pronunciations to those already in the acoustic model lexicon for a given word, they will need to copy the said pronunciations to the user lexicon, and then add them. If any pronunciation is not copied to the user lexicon, it will no longer be accepted in the recognition; therefore, it is possible to remove a given word’s pronunciations. It is important to be aware of this, in order to avoid losing pronunciations unintentionally.
The section Creating user lexicons provides more details on user-defined lexicons. When a word is not found in any lexicon, the automatic G2P tool is invoked. The output of this tool for any word can be checked. To learn more, see the section Evaluating word pronunciations.
Creating user lexicons¶
When creating a grammar, it may be necessary to manually configure the desired pronunciation for certain words. As a rule, this is done to adjust irregularities in the grapheme to phoneme mapping of the target language that could lead to the absence of the correct pronunciation of a word in the available lexicons. Examples of such irregularities are foreign words, brand names, among others.
A user lexicon in text format is a text file, normally saved with the name lexicon.txt, separated in lines containing three fields each, separated by “tab”:
The word.
The pronunciation probability (optional).
The pronunciation, represented by a sequence of phones separated by blank spaces.
See the example of line extracted from a text lexicon for Brazilian Portuguese, corresponding to a lexicon with pronunciation probabilities (“tab” are represented as 8 spaces).
carro 1.0 kk aa rx uc
Pronunciation probabilities are optional. The following line is valid for a text lexicon with no pronunciation probabilities:
carro kk aa rx uc
The presence of pronunciation probabilities are configured on the file level; in other words, lines with and lines without pronunciation probabilities cannot appear in the same file. Pronunciation probabilities must be configured so that 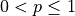 , but their sum does not need to be unitary for each word; the probabilities of pronunciation are adequately normalized during the compilation process. In a lexicon with no pronunciation probabilities, the occurrence of each pronunciation in the input audio is considered equally probable.
, but their sum does not need to be unitary for each word; the probabilities of pronunciation are adequately normalized during the compilation process. In a lexicon with no pronunciation probabilities, the occurrence of each pronunciation in the input audio is considered equally probable.
The phones allowed in the pronunciation field vary according to the target language. The grammar-g2p tool, described in the section Evaluating word pronunciation, is useful for understanding the pronunciation of each phone; this tool can be used to query the transcription of known words and, based on these words, notice how the phones are used in phonetic transcription.
In lexicon files, blank spaces that are not “tab” can appear in every field; in this case, blank spaces at the beginning and end of the field are discarded, and multiple sequential blank spaces are considered a single space (that is, ” word ” and “word ” ) are exactly the same).
Suppose you have a grammar.gram file, with some grammar in the ABNF format. You can add a text lexicon lexicon.txt to the grammar by means of the lexicon declaration in the grammar head.
#ABNF 1.0 UTF-8;
lexicon <lexicon.txt>;
// Corpo da gramática
The lexicon URI, in angular brackets, can also be an absolute or relative path for a file outside the current directory. Web page links (such as HTTP or FTP) are also supported. Multiple lexicons are allowed, but it is important to remember that the procedure described in the section Lexicons and word pronunciations is applied when querying words.
#ABNF 1.0 UTF-8;
lexicon <lexicon1.txt>;
lexicon <../lexicon2.txt>;
lexicon </home/user/grammars/lexicon3.txt>;
// Corpo da gramática
Lexicons can be added to XML grammars using the element <lexicon>.
<grammar xmlns="http://www.w3.org/2001/06/grammar"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2001/06/grammar
http://www.w3.org/TR/speech-grammar/grammar.xsd"
xml:lang="en" version="1.0">
<lexicon uri="lexicon.txt">
<!-- Corpo da gramática -->
Lexicons can be converted to a binary format, in order to be loaded more quickly. This procedure is described in the section Working with binary lexicons. By convention, binary lexicons are saved with the .bin extension. By default, a user lexicon with a .txt extension is interpreted as a text lexicon without pronunciation probabilities, and a lexicon with a .bin extension is interpreted as a binary lexicon (binary lexicons always contain pronunciation probabilities, even when sourced from text lexicons without probabilities). This behavior can be modified by adding a media type to the lexicon URI, according the following table.
Lexicon Type |
Media Type |
|---|---|
Text, without pronunciation probabilities |
lexicon/text |
Text, with pronunciation probabilities |
lexicon/text+probs |
Binary |
lexicon/bin |
See an example of how a media type can be added to the lexicon URI.
#ABNF 1.0 UTF-8;
lexicon <lexicon1>~<lexicon/text>;
lexicon <../lexicon2.txt>~<lexicon/text+probs>;
lexicon </home/user/grammars/lexicon3.xyz>~<lexicon/bin>;
// Corpo da gramática
Lexicons in external grammars¶
It is important to understand the behavior of the grammar compiler regarding lexicons when a grammar file contains a reference to another grammar file. Consider the two grammars, a.gram and b.gram, represented below. The content of the lexicon_a.txt and lexicon_b.txt files is not relevant.
a.gram |
b.gram |
|---|---|
#ABNF 1.0 UTF-8;
lexicon <lexicon_a.txt>;
root $root;
$root = reference to $<b.gram>;
|
#ABNF 1.0 UTF-8;
lexicon <lexicon_b.txt>;
root $root;
$root = this is grammar b;
|
Let’s suppose that grammar a.gram is to be compiled.
$ grammar-compile a.gram
In this case, only the lexicon_a.txt file will be processed; the lexicon_b.txt file will not. This happens because, when a grammar is compiled, only the lexicons directly referenced in the grammar are included; lexicons referenced in external grammars by the grammar being compiled are ignored. Therefore, if you want the lexicon_b.txt file to be included, the reference to it must be moved to the a.gram, as shown in the following table.
a.gram |
b.gram |
|---|---|
#ABNF 1.0 UTF-8;
lexicon <lexicon_a.txt>;
lexicon <lexicon_b.txt>;
root $root;
$root = reference to $<b.gram>;
|
#ABNF 1.0 UTF-8;
// The line below doesn’t need
// to be commented, since
// the reference is ignored.
// lexicon <lexicon_b.txt>;
root $root;
$root = this is grammar b;
|
This behavior is due to the fact that the current ASR library version does not support pronunciations specific to the grammar. In other words, it is impossible to change the pronunciation of a word in an external grammar and, at the same time, maintain the occurrences of that word in the main grammar. Thus, when an auxiliary grammar is referenced by a main grammar, you must be sure that all the words in the auxiliary grammar are present in the main grammar lexicon; if that is not the case, and the auxiliary grammar contains a lexicon file, copy the line that references this lexicon to the main grammar. There is no need to remove the reference to the auxiliary grammar, since it will be ignored.
Working with binary lexicons¶
If you are using a very large lexicon, the time it takes to compile grammars that reference it may be very lengthy. In this case, you can compile text lexicons and generate binary lexicons (and vice-versa). Regarding your corresponding text file, a binary lexicon is typically larger, but it takes less time to be loaded when the grammar is being compiled than the compilation of the grammar where it is being referenced. It is important to observe that, regardless of whether the lexicons referenced by a grammar are binary or texts, the resulting compiled grammar is exactly the same.
For converting one lexicon format to another, the lexicon-convert tool must be used. The tool is invoked with two parameters: a URI specifying the input lexicon and another specifying the output lexicon. See an example below of a binary lexicon based on a text lexicon.
$ lexicon-convert lexicon.txt lexicon.bin
In compliance with the conventions adopted in the section Creating user lexicons, the lexicon.txt file is interpreted as a lexicon without pronunciation probabilities. If a lexicon contains probabilities, a media type is added to the input lexicon URI when the tool is invoked.
$ lexicon-convert "<lexicon.txt>~<lexicon/text+probs>" lexicon.bin
The conversion from binary to text format is similar.
$ lexicon-convert lexicon.bin lexicon.txt
$ # Ou, equivalentemente
$ lexicon-convert lexicon.bin "<lexicon.txt>~<lexicon/text>"
$ lexicon-convert lexicon.bin "<lexicon.txt>~<lexicon/text+probs>"
Evaluating word pronunciation¶
During the creation of user lexicons, it is frequently useful to check which pronunciations have been assigned to a given word (or a set of words). To this end, the ASR library provides a tool called grammar-g2p. We have provided an example below of how this tool can be used to check the pronunciations that have been assigned to some words in Portuguese. The tool output is in the format of a lexicon with pronunciation probabilities:
$ grammar-g2p carro casa maçã
carro 1 kk aa rx uc
casa 1 kk aa zz ac
maçã 1 mm aa ss an
By default, all the pronunciations of the grammar-g2p tool are for Brazilian Portuguese, regardless of the installed acoustic model. Another language can be defined, using the grammar-g2p tool with the ``–lang``option and the target language ID. The only two languages currently supported are Brazilian Portuguese (pt-br) and Latin American Spanish (es). For example, in the case of Spanish:
$ grammar-g2p --lang=es cuatro siete uno
The grammar-g2p tool is also able to transcribe made-up words. This feature is very useful in cases where you wish to obtain the pronunciation of a word, but you are not sufficiently familiar with the set of phones adopted by the ASR library.
$ grammar-g2p tuíter gúgou merchandáizin
tuíter 1 tt uu ii tt ee rf
gúgou 1 gg uu gg oo uw
merchandáizin 1 mm ee rf sh an dd aa ij zz in